
This is the third in a multi-part series in which we explore and compare various deep learning tools and techniques for market forecasting using Keras and TensorFlow. In Part 1, we introduced Keras and discussed some of the major obstacles to using deep learning techniques in trading systems, including a warning about attempting to extract meaningful signals from historical market data. If you haven’t read that article, it is highly recommended that you do so before proceeding, as the context it provides is important. Read Part 1 here. Part 2 provides a walk-through of setting up Keras and Tensorflow for R using either the default CPU-based configuration, or the more complex and involved (but well worth it) GPU-based configuration under the Windows environment. Read Part 2 here. Part 3 is an introduction to the model building, training and evaluation process in Keras. We train a simple feed forward network to predict the direction of a foreign exchange market over a time horizon of hour and assess its performance.. Now that you can train your deep learning models on a GPU, the fun can really start. By the end of this series, we’ll be building interesting and complex models that predict multiple outputs, handle the sequential and temporal aspects of time series data, and even use custom cost functions that are particularly relevant to financial data. But before we get there, we’ll start with the basics. In this post, we’ll build our first neural network in Keras, train it, and evaluate it. This will enable us to understand the basic building blocks of Keras, which is a prerequisite for building more advanced models.
Problem Formulation
There are numerous possible ways to formulate a market forecasting problem. For the sake of this example, we will forecast the direction of the EUR/USD exchange rate over a time horizon of one hour. That is, our model will attempt to classify the next hour’s market direction as either up or down.Data
Our data will consist of hourly EUR/USD exchange rate history obtained from FXCM (IMPORTANT: read the caveats and limitations associated with using past market data to predict the future here). Our data covers the period 2010 to 2017.Features
Our features will simply consist of a number of variables related to price action:- Change in hourly closing price
- Change in hourly highest price
- Change in hourly lowest price
- Distance between the hourly high and close
- Distance between the hourly low and close
- Distance between the hourly high and low (the hourly range)
Feature scaling
Training of neural networks normally proceeds more efficiently if we scale our input features to force them into a similar range. There are various scaling strategies throughout the deep learning literature (see for example Geoffrey Hinton’s Neural Networks for Machine Learning course), but scaling remains something of an art rather than a one-size-fits all type problem. The standard approach to scaling involves normalizing the entire data set using the mean and standard deviation of each feature in the training set. This prevents data leakage from the test and validation sets into the training set, which can produce overly optimistic results. The problem with this approach for financial data is that it often results in scaled test or validation data that winds up being way outside the range of the training set. This is related to the problem of non-stationarity of financial data and is a significant issue. After all, if a model is asked to predict on data that is very different to its training data, it is unlikely to produce good results. One way around this is to scale data relative to the recent past. This ensures that the test and validation data is always on the intended scale. But the downside is that we introduce an additional parameter to our model: the amount of data from the recent past that we use in our scaling function. So we end up introducing another problem to solve an existing one. Like I said, feature scaling is something of an art form, particularly when dealing with data as poorly behaved as financial data! We’ll do our model building and experimentation in R, but first we need to generate our data. There is a Zorro script named ‘keras_data_gen.c’ for creating our targets and scaled features, and for exporting that data to a CSV file in this download link. The script will allow you to code your own features and targets, use different scaling strategies, and generate data for different instruments. Just make the changes, then click ‘Train’ on the Zorro GUI to export the data to file. If you’d prefer to just get your hands on the data used in this post, it’s also available in that same link, as is all the R code used in this post. Our target is the direction of the market over a period of one hour, which implies a classification problem. The target exported in the script is the actual dollar amount made or lost by going long the market at 0.01 lots, exclusive of trading costs. We need to convert this to a factor reflecting the market’s movement either up or down. More on this below. Let’s import our data into R and take a closer look. First, here’s a time series plot of the first ten days of our scaled features: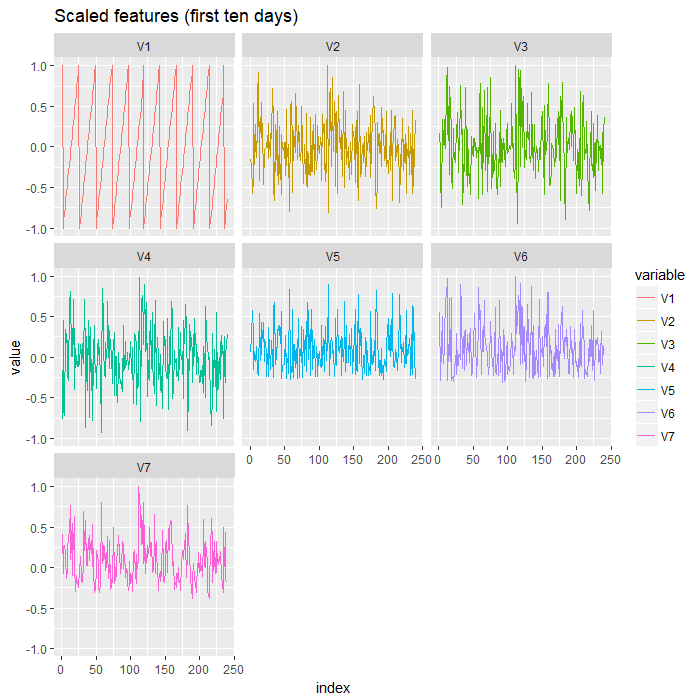 You can see that our features are roughly on the same scale. Notice the first feature, V1, which corresponds to the hour of the day. It has been scaled using a slightly different approach to the other variables to ensure that the cyclical nature of that variable is maintained. See the code in the download link above for details.
Next, here’s a scatterplot matrix of our variables and target (the first ten days of data only):
You can see that our features are roughly on the same scale. Notice the first feature, V1, which corresponds to the hour of the day. It has been scaled using a slightly different approach to the other variables to ensure that the cyclical nature of that variable is maintained. See the code in the download link above for details.
Next, here’s a scatterplot matrix of our variables and target (the first ten days of data only):
 Now that we’ve got our data, we’ll see if we can extract any predictive information using deep learning techniques. In this post, we’ll look at fully connected feed-forward networks, which are kind of the like the ‘Hello World’ example of deep learning. In later posts, we’ll explore some more interesting networks.
Now that we’ve got our data, we’ll see if we can extract any predictive information using deep learning techniques. In this post, we’ll look at fully connected feed-forward networks, which are kind of the like the ‘Hello World’ example of deep learning. In later posts, we’ll explore some more interesting networks.
Fully Connected Feed Forward Networks
A fully connected feed forward network is one in which every neuron in a particular layer is connected to every neuron in the subsequent layer, and in which information flows in one direction only, from input to output. Here’s a schematic of such a network with an input layer, two hidden layers and an output layer consisting of a single neuron (source: datasciencecentral.com):
Input data processing
It makes sense that our network would likely benefit from using not only the features for the current time step, but also a number of prior values as well, in order to predict the target. That means that we need to create features out of lagged values of our raw feature variables. Thankfully, that’s easily accomplished using base R’s embed() function, which also automatically drops the NA values which arise in the first (n) observations, where (n) is the number of lags to use as features. Here’s a function which returns an expanded data set consisting of the current features as well as their lags lagged values. It assumes that the target is in the final column (and doesn’t embed lagged values of the target) and drops the relevant NA values from the target column.# function for creating features from lagged variables
lag_variables_to_features <- function(data, num_lags=1) {
d <- embed(data[, -ncol(data)], num_lags+1) # this automatically drops NA, assumes target in last column
d <- cbind(d, data[(num_lags+1):nrow(data), ncol(data)]) # add column for target, dropping num_lags
return(d)
}
Let’s test the function and take a look at its output:
# test lagging function set.seed(503) dat <- replicate(3, rnorm(10, 0, 1)) dat # [,1] [,2] [,3] # [1,] 0.355125070 -0.42202083 2.2040012 # [2,] -0.778893409 -0.03744167 0.4128119 # [3,] -0.757356957 -0.20609016 1.0322519 # [4,] 2.329800607 2.01835389 0.7804746 # [5,] 0.283974926 -0.60559854 2.5843431 # [6,] 1.281025216 -0.28414168 0.2339200 # [7,] -0.002363249 0.96044445 1.3501947 # [8,] 1.033770690 0.74774752 -0.4097266 # [9,] -0.431933268 -0.01286499 -0.3662180 # [10,] -0.342867464 -0.71862991 -1.0912861 dat <- lag_variables_to_features(dat, 2) dat # [,1] [,2] [,3] [,4] [,5] [,6] [,7] # [1,] -0.757356957 -0.20609016 -0.778893409 -0.03744167 0.355125070 -0.42202083 1.0322519 # [2,] 2.329800607 2.01835389 -0.757356957 -0.20609016 -0.778893409 -0.03744167 0.7804746 # [3,] 0.283974926 -0.60559854 2.329800607 2.01835389 -0.757356957 -0.20609016 2.5843431 # [4,] 1.281025216 -0.28414168 0.283974926 -0.60559854 2.329800607 2.01835389 0.2339200 # [5,] -0.002363249 0.96044445 1.281025216 -0.28414168 0.283974926 -0.60559854 1.3501947 # [6,] 1.033770690 0.74774752 -0.002363249 0.96044445 1.281025216 -0.28414168 -0.4097266 # [7,] -0.431933268 -0.01286499 1.033770690 0.74774752 -0.002363249 0.96044445 -0.3662180 # [8,] -0.342867464 -0.71862991 -0.431933268 -0.01286499 1.033770690 0.74774752 -1.0912861You can see that the function returns a new dataset with the current features and their last two lagged values, while the target remains unchanged in the final column. Note that the two rows that wind up with NA values are automatically dropped. Essentially, this approach makes new features out of lagged values of each feature. But here’s the thing about feed forward networks: they don’t distinguish between more recent values of our features and older values. Obviously the network differentiates between the different features that we create out of lagged values, and has the ability to discern relationships between them, but it doesn’t explicitly factor the sequential nature of the data. That’s one of the major limitations of fully connected feed forward networks applied to time series forecasting exercises, and one of the motivators of recurrent architectures, which we will get to soon enough.
Introducing the Keras sequential model
Now that we can process our input data, we can start experimenting with the model building process. The best place to start is Keras’ sequential model, which is essentially a paradigm for constructing deep neural networks, one layer at a time, under the assumption that the network consists of a linear stack of layers and has only a single set of inputs and outputs. You’ll find that this assumption holds for the majority of networks that you build, and it provides a very modular and efficient method of experimenting with such networks. We’ll use the sequential model quite a lot over the coming posts before getting into some more complex models that don’t fit this paradigm. In Keras, the model building and exploration workflow typically consists of the following steps:- Define the input data and the target. Split the data into training, validation and test sets.
- Define a stack of layers that will be used to predict the target from the input. This is the step that defines the network architecture.
- Configure the model training process with an appropriate loss function, optimizer and various metrics to be monitored.
- Train the model by repeatedly exposing it to the training data and updating the network weights according to the loss function and optimizer chosen in the previous step.
- Evaluate the model on the test set.
Set up our data
Here’s some code for loading and processing our data. It firstly loads the data set we created with our Zorro script from above and creates a new data set consisting of the current value of each feature, as well as the seven recent lagged variables. That is, we have a total of eight timesteps for each feature. And since we started with 7 features, we have a total of 56 input variables. We also split the dataset into a training, validation and testing set. Here, I arbitrarily chose to use 50% of the data for training, 25% for validation and 25% for testing. Note that since the time aspect of our data is critical, we should ensure that our training, validation and testing data are not randomly sampled as is standard procedure in many non-sequential applications. Rather, the training, validation and test sets should come from chronological time periods. Note that we convert our target into a binary outcome, which enables us to build a classifier. Recall that we scaled our features at the same time as we generated them, so no need to do any feature scaling here.## load, process and split data ## # load path <- "C:/Users/Kris/Data/" XY <- read.csv(paste0(path, 'EURUSD_L_2010_2017.csv'), header = F) XY <- as.matrix(XY) # create lags lags <- 7 proc <- lag_variables_to_features(XY, lags) # split into training, validation and test sets train_length <- floor(0.5*nrow(proc)) val_length <- floor(0.25*nrow(proc)) X_train <- proc[1:train_length, -ncol(proc)] Y_train_raw <- proc[1:train_length, ncol(proc)] Y_train <- ifelse(Y_train_raw > 0, 1, 0) X_val <- proc[(train_length+1):(train_length+val_length), -ncol(proc)] Y_val_raw <- proc[(train_length+1):(train_length+val_length), ncol(proc)] Y_val <- ifelse(Y_val_raw > 0, 1, 0) X_test <- proc[(train_length+val_length+1):nrow(proc), -ncol(proc)] Y_test_raw <- proc[(train_length+val_length+1):nrow(proc), ncol(proc)] Y_test <- ifelse(Y_test_raw > 0, 1, 0)
Define network architecture
Next we define the stack of layers that will become our model. The syntax might seem quirky at first, but once you’re used to it, you’ll find that you can build and experiment with different architectures very quickly. The syntax of the sequential model uses the pipeline operator %>% which you might be familiar with if you use the dplyr package. In essence, we define a model using the sequential paradigm, and then use the pipeline operator to define the order in which layers are stacked. Here’s an example:model <- keras_model_sequential() model %>% layer_dense(units = 150, activation = 'relu', input_shape = ncol(X_train)) %>% layer_dense(units = 150, activation = 'relu') %>% layer_dense(units = 150, activation = 'relu') %>% layer_dense(units = 1, activation = 'sigmoid')This defines a fully connected feed forward network with three hidden layers, each of which consists of 150 neurons with the rectified linear (‘relu’ ) activation function. If you need a refresher on activation functions, check out this post on neural network basics. layer_dense() defines a fully connected layer – that is, one in which each input is connected to every neuron in the layer. Note that for the first layer, we need to define the input shape, which is simply the number of features in our data set. We only need to do this on the first layer; each subsequent layer gets its input shape from the output of the prior layer. layer_dense() has many arguments in addition to the activation function that we specified here, including the weight initialization scheme and various regularization settings. We use the defaults in this example. Keras implements many other layers, some of which we’ll explore in subsequent posts. In this example, our network terminates with an output layer consisting of a single neuron with the sigmoid activation function. This activation function converts the output to a value between 0 and 1, which we interpret as the probability associated with the positive class in a binary classification problem (in this case, the value 1, corresponding to an up move). To get an overview of the model, call summary(model) and observe the output:
___________________________________________________________________________________________________ Layer (type) Output Shape Param # =================================================================================================== dense_1 (Dense) (None, 150) 8550 ___________________________________________________________________________________________________ dense_2 (Dense) (None, 150) 22650 ___________________________________________________________________________________________________ dense_3 (Dense) (None, 150) 22650 ___________________________________________________________________________________________________ dense_4 (Dense) (None, 1) 151 =================================================================================================== Total params: 54,001 Trainable params: 54,001 Non-trainable params: 0 ___________________________________________________________________________________________________ >This model architecture could be better described as ‘wide’ as opposed to ‘deep’ and it consists of around 54,000 trainable parameters. This is more than the number of observations in our data set, and has implications for the ability of our network to overfit.
Configure the training process
Configuration of the training process is accomplished via the keras::compile() function, in which we specify a loss function, an optimizer, and a set of metrics to monitor during training. Keras implements a suite of loss functions, optimizers and metrics out of the box, and in this example we’ll choose some sensible defaults:model %>% compile(
loss = 'binary_crossentropy',
optimizer = optimizer_rmsprop(lr=0.0001),
metrics = c('accuracy')
)
The ‘binary_crossentropy’ loss function is standard for binary classifiers and the rmsprop() optimizer is nearly always a good choice. Here we specify a learning rate of 0.0001, but finding a sensible value typically requires some experimentation. Finally, we tell Keras to keep track of our model’s accuracy, as well as the loss during the training process.
An important consideration regarding loss functions for financial prediction is that the standard loss functions rarely capture the realities of trading. For example, consider a regression model that predicts a price change over some time horizon trained using the mean absolute error of the predictions. Say the model predicted a price change of 20 ticks, but the actual outcome was 10 ticks. In practical trading terms, such an outcome would result in a profit of 10 ticks – not a terrible outcome at all. But that result is treated the same as a prediction of 5 ticks that resulted in an actual outcome of -5 ticks, which would result in a loss of 5 ticks in a trading model. That’s because the loss function is only concerned with the magnitude of the difference between the predicted and actual outcomes – but that doesn’t tell the full story. Clearly, we’d likely to penalize the latter error more than the former. To do that, we need to implement our own custom loss functions. I’ll show you how to do that in a later post, but for now it’s important to be cognizant of the limitations of our model training process.
Train the model
We can train our model using keras::fit() , which exposes our model to subsequent batches of training data, updating the network’s weights after each batch. Training progresses for a specified number of epochs and performance is monitored on both the training and validation sets. We would normally like to stop training at the number of epochs that maximize the model’s performance on the validation set. That is, at the point just before the network starts to overfit. The problem is we can’t know a priori how many training epochs this requires. To combat this, keras::fit() implements the concept of a callback, which is simply a function that performs some task at various points throughout the training process. There are a number of callbacks available in Keras out of the box, and it is also possible to implement your own. In this example we’ll use the model_checkpoint() callback, which we configure to save the network and it’s weights at the end of any epoch whose weight update results in improved validation performance. After training is complete, we can then load our best model for evaluation on the test set. First, here’s how to configure the checkpoint callback (just set up the relevant filepath for your setup):filepath <- "C:/Users/Kris/Research/DeepLearningForTrading/model.hdf5"
checkpoint <- callback_model_checkpoint(filepath = filepath, monitor = "val_acc", verbose = 1,
save_best_only = TRUE,
save_weights_only = FALSE, mode = "auto")
And here’s how to configure keras:fit() for a short training run of 75 epochs, with the model checkpoint callback:
history <- model %>% fit( X_train, Y_train, epochs = 75, batch_size = nrow(X_train), validation_data = list(X_val, Y_val), shuffle = TRUE, callbacks = list(checkpoint) )After training is complete, we can plot the loss and accuracy of the training and validation sets at each epoch by simply calling plot(history) , which results in the following plot:
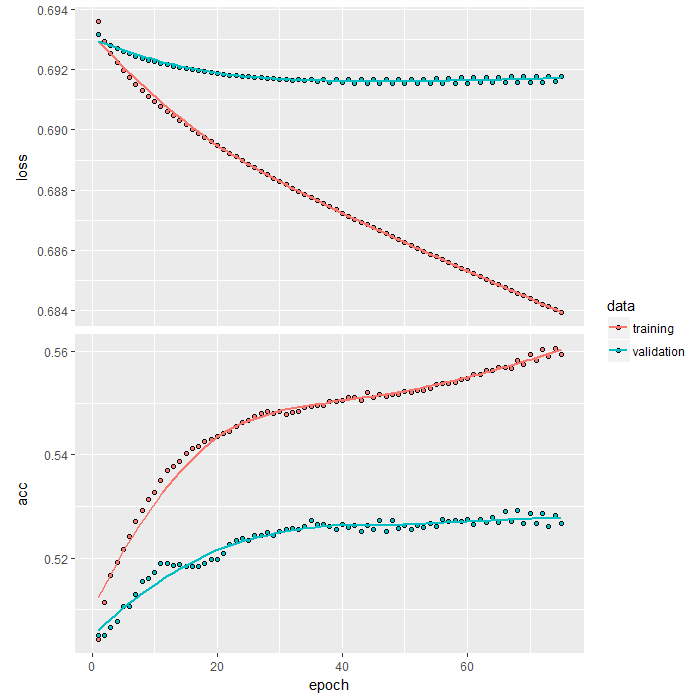 We can see that loss on the training set continuously decreases while accuracy almost continuously increases as training progresses. That is expected given the power of our network to overfit. But note the small decrease in validation loss and the bump in validation accuracy that we also get out to about 40 epochs before stalling.
A validation accuracy of a little under 53% is certainly not the sort of result that would turn heads in the classic applications of deep learning, like image classification. But trading is an interesting application, because we don’t necessarily need the same sort of performance to make money. But is a validation accuracy of 53% enough to give us some out of sample profits? Let’s find out by evaluating our model on the test set.
We can see that loss on the training set continuously decreases while accuracy almost continuously increases as training progresses. That is expected given the power of our network to overfit. But note the small decrease in validation loss and the bump in validation accuracy that we also get out to about 40 epochs before stalling.
A validation accuracy of a little under 53% is certainly not the sort of result that would turn heads in the classic applications of deep learning, like image classification. But trading is an interesting application, because we don’t necessarily need the same sort of performance to make money. But is a validation accuracy of 53% enough to give us some out of sample profits? Let’s find out by evaluating our model on the test set.
Evaluate the model out of sample
Here’s how to remove the fully trained model, load the model with the highest validation accuracy and evaluate it on the test set, with the output shown below the code:rm(model) model <- keras:::keras$models$load_model(filepath) model %>% evaluate(X_test, Y_test) # output: # 12004/12004 [==============================] - 2s 197us/step # $loss # [1] 0.691 # $acc # [1] 0.523We end up with a test set accuracy that is only slightly worse than our validation accuracy. But accuracy is one thing, profitability is another. To assess the profitability of our model on the test set, we need the actual predictions on the test set. We can get the predicted classes via predict_classes() , but I prefer to look at the actual output of the sigmoid function in the final layer of the model. That enables you to use a prediction threshold in your decision making, for example only entering a long trade when the output is greater than 0.6, say. Here’s how to get the test set predictions and implement some simple, frictionless trading logic that assigns the target as an individual trade’s profit or loss when the prediction is greater than some threshold (equivalent to a buy) and the negative of the target when the prediction is less than 1 minus the threshold (equivalent to a sell) :
preds <- model %>% predict_proba(X_test) threshold <- 0.5 trades <- ifelse(preds >= threshold, Y_test_raw, ifelse(preds <= 1-threshold, -Y_test_raw, 0)) plot(cumsum(trades), type='l')This results in the following equity curve (the y-axis is measured in dollars of profit from buying and selling the minimum position size of 0.01 lots):
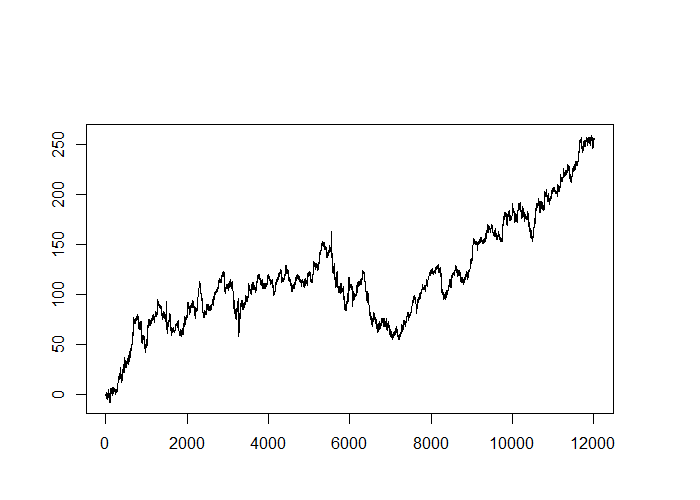 I think that’s quite an amazing equity curve that demonstrates the potential of even a very small edge. However, note that adding typical retail transaction costs would destroy this small edge, which suggests that longer holding periods are more sensible targets, or that higher accuracies are required in practice.
Also note that you might get different results depending on the initial weights used in your network, as the weights aren’t guaranteed to converge to the same values when initialized to different values. If you repeat the training and evaluation process a number of times, you’ll find that validation accuracies in the range of 52-53% occur most of the time, but while most produce profitable out of sample equity curves, the range of performance is actually quite significant. This implies that there might be benefit in combining the predictions of multiple models using ensemble methods.
I think that’s quite an amazing equity curve that demonstrates the potential of even a very small edge. However, note that adding typical retail transaction costs would destroy this small edge, which suggests that longer holding periods are more sensible targets, or that higher accuracies are required in practice.
Also note that you might get different results depending on the initial weights used in your network, as the weights aren’t guaranteed to converge to the same values when initialized to different values. If you repeat the training and evaluation process a number of times, you’ll find that validation accuracies in the range of 52-53% occur most of the time, but while most produce profitable out of sample equity curves, the range of performance is actually quite significant. This implies that there might be benefit in combining the predictions of multiple models using ensemble methods.
What’s next?
Before we get into advanced model architectures, in the next unit I’ll show you:- How to fight overfitting and push your models to generalize better.
- One of the more cutting edge architectures to get the most out of a densely connected feed forward network.
- How to interrogate and visualize the training process in real time.
Conclusions
This post demonstrated how to process multivariate time series data for use in a feed forward neural network, as well as how to construct, train and evaluate such a network using Keras’ sequential model paradigm. While we uncovered a slim edge in predicting the EUR/USD exchange rate, in practical terms, traders with access to retail spreads and commission will want to consider longer holding times to generate more profit per trade, or will need a more performant model to make money with this approach.Where to from here?
- To find out why AI is taking off in finance, check out these insights from my days as an AI consultant to the finance industry
- If this walk-through was useful for you, you might like to check out another how-to article on running trading algorithms on Google Cloud Platform
- If the technical details of neural networks are interesting for you, you might like our introductory article
- Be sure to check out Part 1 and Part 2 of this series on deep learning applications for trading.
Free Case Study:
A wantaway engineer’s journey into professional trading and out again
I went from engineering to an equity partnership at a prop trading firm to running my own systematic trading operation from home in Western Australia.
This case study is the full story – every mistake, every breakthrough, and some things I trade today.




Kris,
Download links are missing/broken…
Regards,
Tom
Hey Tom, thanks for the heads up. That’s really weird – they are working fine for me (tested on Windows + Chrome, Edge and Firefox). What OS/browser are you using? I can email you the content if you like.
Anyone else having trouble with the download links?
Doesn’t work for me both in Chrome and Edge on Windows and Android. Links look like this: Download the code and data used in this post here.
I mean like this >a data-sumome-listbuilder-id=”a9e77072-02f8-45f4-b0d7-0137643863ec”>Download the code and data used in this post here.a<
So strange! I can’t reproduce the error and so far you’re the only one. Thanks for letting me know, and I will email you the material instead.
If anyone else has a similar issue, just post in the comments!
Hello Kris,
Amazing Post! really insightful and inspirational.
May I bother you with a couple of questions?
When you scale the first feature, V1, which corresponds to the hour of the day, what scaling kind do you refer to?
I am playing with a similar problem and I found the overfitting a major problem. Could you give me some tips to try to overcome the problem?
Thanks in advance for your help, and I will be tuned for the next post 🙂
Jonathan Moreno Narváez
Hi Jonathon,
Thanks for the feedback! Glad to hear you liked the post.
You can see exactly how I scaled V1 in the Zorro script in the download link, but here’s the formula:
V1_scaled <- 2*(V1-min(V1))/(max(V1)-min(V1)) - 1 Since raw V1 is on the interval [0, 23], this reduces to: V1_scaled = 2*V1/23 - 1 Overfitting is a huge problem! That's the subject of the next post, but if you want to get a head start, look into dropout, batch normalization, batch renormalization, and (for feed-forward nets) the concept of self-normalizing architectures.
Thanks for reading!
Hi Kris,
again, the quality and depth of your blog makes it one of the most useful and inspriring resources to be found on the internet. It’s filling the void between scientific articles which can be very laborious to implement and all the naïve examples trying to popularize machine learning, but which at the end of the day add very little of substance. At least not if you’re indeed trying to build something that works in practice. So – hat’s off.
Now – I’ve been working on a reinforcement learning agent for the last couple of months and I’m just about to abandon the discrete universe of the Q-table for a deep model with a continuous state space. Is this something you have looked into at any point? It would be very interesting to hear your thoughts on such models in general.
Kind Regards,
Per
Hi Per,
Thank you for the kind words! It really means a lot to hear that my work is resonating with people and provides value. So thank you greatly for the feedback.
Q-learning (and reinforcement learning generally) actually represents a bit of a gap in my experience. However, it is on my list of projects to explore this year and would make a sensible topic after the current Keras series is finished. It would be great to share experiences when that time comes, so I hope you keep visiting the blog!
Cheers
Kris
Hi Kris
excellent articles! great to see practical applications of DNN
to avoid overfitting it is also possible to use earlystopping, I guess you are probably aware of that
https://keras.io/callbacks/#earlystopping
do you have guidelines for the hyperparams of of the network:
-why 150 nodes? and not 300? or any other…and why equally distributed between the layers?
– why 2 hidden layers and not just 1? ou 3 ? or 10? do you have any guidelines to decide how many layers to use?
have you used LSTMs ? it is suppose to be better suited for time series there is a dropout component that allows do give different weightings to the timesteps/lags in the time series
I think the biggest problem with machine learning or any other statistical method when applied to finance time series it that they are not stationary, even if a trade system looks good out of sample (OOS) there are no guarantees it will work in the future
Hi Ricardo,
Many thanks for the kind words! I’m really glad you found the article useful.
We have plans to address pretty much all of the points you raise throughout the series, but at the risk of spoiling the surprise, I’ll address them all briefly here.
Early stopping: Yeah that’s generally a good idea! I prefer to use Keras’ checkpoint callback so that I can assess the entire training process of my network (beyond the point of overfitting) while being able to retrieve the optimal model. I’ll go into more detail about callbacks in the next couple of posts.
Number of layers, nodes and other hyperparameters: this is something of an art and there are no hard and fast rules. Bengio et. al. published some rules of thumb in a paper a while back, which is worth reading if you haven’t done so already. Search “Practical Recommendations for Gradient-Based Training of Deep Architectures” and you should be able to find it. The architecture I chose here was rather arbitrary and mainly for the purposes of demonstration. I didn’t want an overly deep network, but some very quick experimentation revealed that wider networks tended to provide a bump to validation accuracy. I didn’t explore the space of possibilities in any detail though, so don’t read too much into my choices.
LSTM: yes, I have used LSTM and other recurrent architectures, like GRU. We’ll get to those shortly. Dropout doesn’t actually give different weightings to timesteps/lags (maybe you’re thinking of L1/L2 regularization?), rather it zeroes the output of the activation function of random nodes during training. One needs to take care when using dropout on recurrent architectures – specifically, the same pattern of dropout needs to be applied at every timestep.
I think the biggest problem with machine learning or any other statistical method when applied to finance time series it that they are not stationary, even if a trade system looks good out of sample (OOS) there are no guarantees it will work in the future: I agree wholeheartedly with both these points!
Hi Kris!
many thanks for your comments , I am looking forward to your updates on this series.
regarding the last point, to handle non-stationarity: there are many possible ways to tackle this: like some sort of regime change identification or maybe to use some non-linear position sizing function: in periods of good performance we should scale up capital allocation aggressively and in bad periods scale down aggressively.
What is your recommendation ?
Regime prediction change is something of a holy grail in the world of trading. If you nail that, then the rest would be pretty easy! In reality though it’s quite difficult (some would say impossible), except in hindsight of course. That’s not to see it isn’t worthy of effort though. If I were tackling that particular problem, I’d probably start by using unsupervised learning (like k-means clustering) to try to find a set of features that clustered your market data nicely and then seeing if those clusters correspond to the next time period’s ‘regime’. You could also try supervised learning, but then you need a target (that is, you need to define what constitutes a particular ‘regime’). Finally, it could be worth exploring the mixture of experts approach, having divided your data into appropriate regimes.
All worked flawlessly with Cuda 9.0/cuDNN 7.1 (had error with 8.0)! Although my 1080ti only got to 1% utilization with CPU at 25% during training (took about a minute). The card’s core clock did jump to max, so all looks fine )
Hi Kris,
The most important moment in machine learning you have little attention. Selection, transformation, evaluation of predictors. This is the main and most time consuming part. But the result depends on it by 80%.
Vlad
Good call Vlad! Couldn’t agree more that feature engineering is the most time consuming aspect of machine learning research. For those interested, we cover that in some detail here:
https://robotwealth.com/machine-learning-financial-prediction-david-aronson/
Hello,
I think the keras_data_gen.c download link is not working, both on Chrome and Edge on Windows. Can you email me the script, please?
Thanks,
Andrew