
Augmented Dickey-Fuller Test
If the time series is not a random walk, the current value tells us something about the next value in the series. If the series is mean reverting, a value above the mean will more likely be followed by a down move and vice versa. The Augmented Dickey-Fuller (ADF) test is a test for the tendency of the series to mean revert based on this observation. Using a linear model of price changes:Δy(t) = λy(t − 1) +βt + μ + α1Δy(t − 1) + … + αkΔy(t − k) + εt
where Δy(t) ≡ y(t) − y(t − 1), Δy(t − 1) ≡ y(t − 1) − y(t − 2), etc.
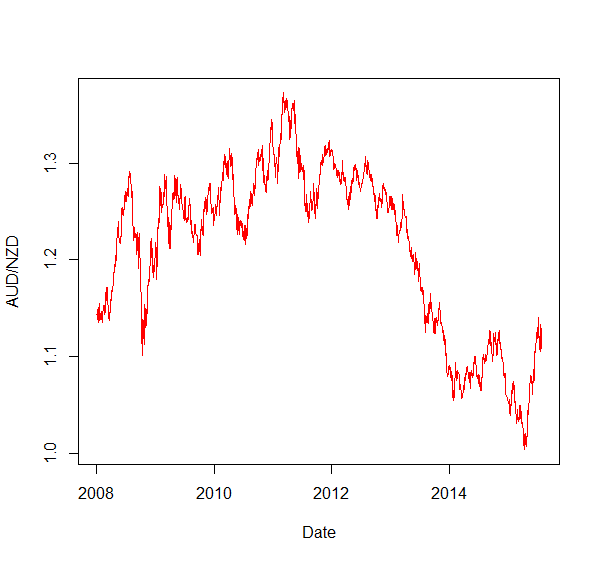
we can see that if λ ≠ 0, then Δy(t) depends on the current level y(t − 1) and therefore is not a random walk. The ADF test examines whether the hypothesis λ = 0 can be rejected at a given confidence level. The following R code (truncated here, full code linked below) examines mean reversion of daily price data for the AUD/NZD exchange rate for the period 2008 to mid-2015. The code uses the ur.df function from the urca package, which contains a number of econometric functions. There is also the adf.test function from the tseries package, but this implementation includes only one of the three variations of the ADF test, and the particular implementation in that package is not suitable for this case. In this application, we should set the drift term to zero because the constant drift in price tends to be of a much smaller magnitude than the daily fluctuations in price (Chan, 2013). The intercept however should be non-zero. This combination is achieved by using the drift argument of the ur.df function. In addition, Chan suggests starting with a lag of 0, but that better results are usually obtained with a lag of 1, which may indicate serial correlation of price changes.library(zoo) library(urca) ########## #Import data ... ... ########## # ADF test summary(ur.df(audnzd, type = "drift", lags = 1))We may expect a degree of mean reversion in this time series given that each currency in the pair is a so-called commodity currency and the two countries inhabit the same corner of the globe. Therefore, they may share a number of market factors. However, the time series doesn’t look overly stationary:
 The results of the ADF test are as follows:
The results of the ADF test are as follows:
###############################################
# Augmented Dickey-Fuller Test Unit Root Test #
###############################################
Test regression drift
Call:
lm(formula = z.diff ~ z.lag.1 + 1 + z.diff.lag)
Residuals:
Min 1Q Median 3Q Max
-0.026807 -0.003564 -0.000072 0.003334 0.035011
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.0026755 0.0019258 1.389 0.165
z.lag.1 -0.0022207 0.0015837 -1.402 0.161
z.diff.lag -0.0009535 0.0226825 -0.042 0.966
Residual standard error: 0.006004 on 1945 degrees of freedom
Multiple R-squared: 0.001015, Adjusted R-squared: -1.27e-05
F-statistic: 0.9876 on 2 and 1945 DF, p-value: 0.3726
Value of test-statistic is: -1.4023 0.9922
Critical values for test statistics:
1pct 5pct 10pct
tau2 -3.43 -2.86 -2.57
phi1 6.43 4.59 3.78
In the urca implementation, the λ term in our linear model above is the estimate of z.lag.1 divided by its standard error, and our critical values corresponds to tau2. In this case, the test statistic is -1.402. This is greater than the the 10% critical value, so we can’t reject the null hypothesis that λ=0 with even 90% certainty and should conclude that the time series is therefore not mean reverting. Interestingly, the negative value for lambda indicates that the time series is at least not trending.
Hurst exponent
Another way of looking at stationarity and mean reversion is from the perspective of the speed of diffusion from an initial state. A stationary series would diffuse at a slower rate than a geometric random walk. We can measure the speed of diffusion as the variance of the series:Var(τ) = 〈|z(t + τ) − z(t)|^2〉
where
- z = log(price)
- τ is an arbitrary time lag
- 〈…〉 is an average over all t’s
For a geometric random walk:
〈|z(t + τ) − z(t)|^2〉 ∼ τ
But if the series is either mean reverting or trending, this relationship will not hold, and instead we get〈|z(t + τ) − z(t)|^2〉 ∼ τ^2H
Where H is the Hurst exponent, H serves as an indicator of the degree to which a series trends. For a trending series, H > 0.5, for a mean-reverting series, H < 0.5 and for a geometric random walk, H = 0.5 (Chan, 2013).
The pracma package in R can be used to to calculate the Hurst exponent. See this for an interesting account of the origins of the Hurst exponent as well as a description of the pracma implementation.
library(pracma) # Hurst exponent hurst <- hurstexp(log(audnzd)) # returns a list of various Hurst calculationsThe hurstexp function returns a list of variously corrected and modified values for H, whose determination is a problem of estimation more than a problem of calculation.
Simple R/S Hurst estimation: 0.8821693 Corrected R over S Hurst exponent: 1.00354 Empirical Hurst exponent: 0.9588154 Corrected empirical Hurst exponent: 0.9422138 Theoretical Hurst exponent: 0.5349181These results suggest that the time series is not mean-reverting, but instead has a tendency to trend.
Half life of mean reversion
At this point, we can step away from the constraints of statistical tests and the demands of 95% confidence limits. One of the interesting aspects of trading is that it is sometimes possible to be profitable despite not achieving the demanding requirements of significance imposed by a statistical test. The challenge is understanding when such a situation may arise and when moving away from statistical significance is likely to lead to disaster. One example of the former case may involve using a time series’ half life of mean reversion as the basis of a mean reversion strategy. An alternate interpretation of the lambda coefficient defined above is the time that a series takes to mean revert (Chan, 2013). To see this interpretation, simply transform the discrete time series model described above to a differential form. Ignoring the drift and lagged difference terms, the differential form is equivalent to the Ornstein-Uhlenbeck stochastic process.dy(t) = (λy(t − 1) + μ)dt + dε
where ε is Guassian noise. This differential form leads to an analytical solution for the expected value of y(t):
E( y(t)) = y0exp(λt) − μ/λ(1 − exp(λt))
which, for a mean reverting process with negative λ, tells us that the expected value of the price decays exponentially at a half-life of -log(2)/λ
If we determine λ to be positive, we can infer that the price series is trending and therefore should not be traded in a mean-reverting strategy. If λ is close to zero, the half life will be very long and any mean reverting strategy will necessarily require long holding times. If λ is very negative, it is more likely that a profitable and practical mean reversion strategy exists since the price series tends to revert to the mean quickly. In his discussion of this idea, Chan (2013) also asserts that λ should be used in calculating lookback periods of moving averages and standard deviations for a mean reverting strategy, with a small multiple of λ often being optimal.
The following R code calculates the half life of mean reversion of our AUD/NZD exchange rate data. To determine λ, regress y(t) − y(t − 1) against y(t − 1):
########## # Calculate half life of mean reversion y <- audnzd y.lag <- lag(y, -1) delta.y <- diff(y) df <- cbind(y, y.lag, delta.y) df <- df[-1 ,] #remove first row with NAs regress.results <- lm(delta.y ~ y.lag, data = df) lambda <- summary(regress.results)$coefficients[2] half.life <- -log(2)/lambdaIn this case, the half life is calculated to be 311 days. At first glance, this feels far too long for this impatient trader! Below I will present a simple trading strategy to test whether this series is exploitable via mean reversion methods.
A simple linear mean reverting strategy
A simple linear mean reverting strategy is realised by determining the normalised deviation of price from its moving average (essentially, a moving Z-score of the last closing price) and holding a position negatively proportional to this deviation. The lookback period for the moving average and moving standard deviation is set equal to the half life of mean reversion. Of course, a moving average and moving standard deviation are required because even though we implicitly assume a stationary price series, in reality it is likely to evolve. In addition, the variance of a mean reverting process does change with time, albeit not as quickly as a geometric random walk. The Zorro code below implements this linear strategy. The number of lots held is equivalent to the negative of the Z-score to account for the fact that a positive Z-score implies a downwards reversion and a negative Z-score implies a positive reversion. Note that the market value is units of the quote currency (AUD in this case). If this is not the account currency, an allowance would need to be made for converting the profits and losses to the account currency. The presentation of this strategy is intended as a proof of concept only and is not practical for live trading. Transaction costs are excluded from the analysis, but would likely be significant given the constant rebalancing of the position. There is also some look ahead bias in that the lookback period for the Z-score calculations was derived from the price history being traded. In the next post, I’ll introduce some examples of more practical methods for exploiting mean reversion.int lotsOpen() {
string CurrentAsset = Asset;
int val = 0;
for(open_trades)
if(strstr(Asset,CurrentAsset) && TradeIsOpen)
val += TradeLots;
return val;
}
function run() {
set(LOGFILE);
BarPeriod = 1440;
StartDate = 2008;
EndDate = 2015;
Spread = Slippage = RollShort = RollLong = 0; // set transaction costs to zero
PlotWidth = 750;
int halfLife = 311;
LookBack = halfLife+1;
vars Close = series(priceClose());
vars zScore = series(10*(-(Close[0] - SMA(Close, halfLife))/StdDev(Close, halfLife))); // multiply by 10 as minimum lot size is 1
int openLots;
if (zScore[0] > 0) { //want to be long the asset
exitShort();
openLots = lotsOpen();
if (openLots < zScore[0]) {//need to buy more
Lots = zScore[0] - openLots;
enterLong();
}
else if (openLots > zScore[0]) {
exitLong(0,0,(openLots - zScore[0])); //need to close some
}
}
else if (zScore[0] < 0) { //want to be short the asset
exitLong();
openLots = lotsOpen();
if (openLots < abs(zScore[0])) { //need to sell more
Lots = abs(zScore[0]) - openLots;
enterShort();
}
else if (openLots > abs(zScore[0])) {
exitShort(0,0,(openLots - abs(zScore[0])));
}
}
plot("zScore", zScore, NEW, BLUE);
plot("MAve", SMA(Close, halfLife), NEW, GREEN);
plot("MSD", StdDev(Close, halfLife), NEW, RED);
}
The strategy returns a respectable 22% per annum, albeit with a significant drawdown and a Sharpe ratio of only 0.39:
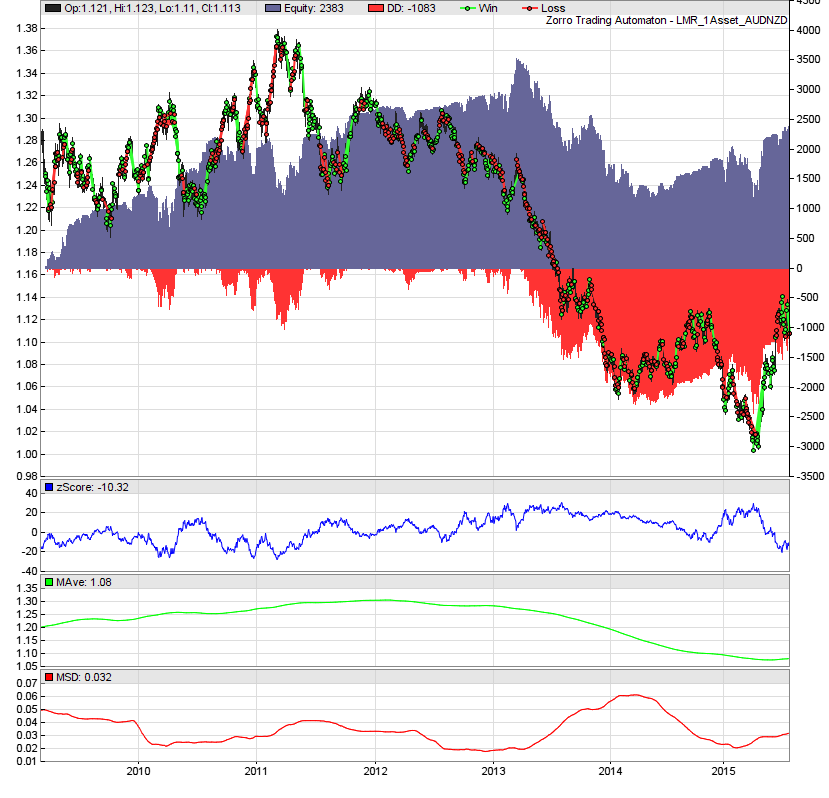 Interestingly, note how the strategy suffers its greatest drawdown at the same time as price breaks its multi-year low in early 2013 and then trends strongly to what appears to be a new range. Note the behaviour of the moving average and the moving standard deviation during this period: their rates of change both increase dramatically. This implies a simple filter based on the rate of change of these series, which leads predictably to a tempering of the maximum drawdown:
Interestingly, note how the strategy suffers its greatest drawdown at the same time as price breaks its multi-year low in early 2013 and then trends strongly to what appears to be a new range. Note the behaviour of the moving average and the moving standard deviation during this period: their rates of change both increase dramatically. This implies a simple filter based on the rate of change of these series, which leads predictably to a tempering of the maximum drawdown:
// simple filter based on rate of change of moving average
vars ma = series(SMA(Close, halfLife));
vars delta = series(100 *(ma[0] - ma[1]));
var threshold = 0.045;
if (abs(delta[0]) < threshold) {
...
// trade normally //
...
}
else if (abs(delta[0]) > threshold) { // exit open trades if rate of change exceeds threshold
exitLong("*"); exitShort("*");
}
plot("delta", delta, NEW, BLUE);
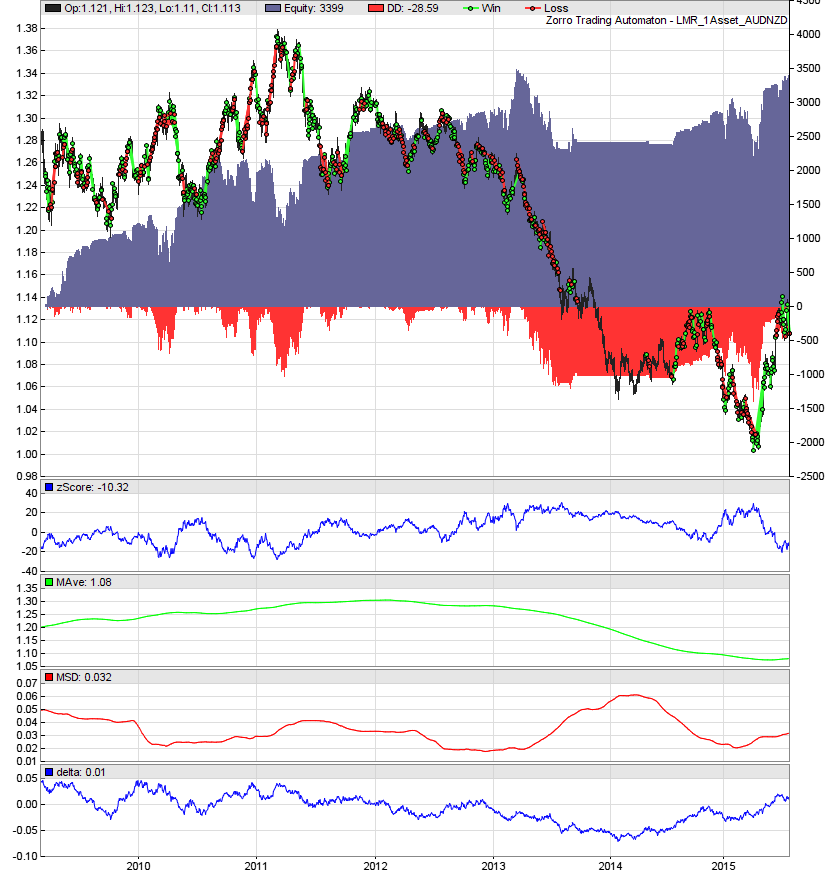 The threshold parameter, which controls the operation of the filter, is an optimization parameter that may or may not hold up out of sample. There are of course numerous options for detecting so-called ‘regime change’ – in this context, when a price series transitions from having a mean-reverting character to trending – including, for example, a rolling ADF test, the Hurst exponent, even the half life of mean reversion itself, or more generally, the coefficient obtained by regressing the bar-to-bar price change against the lagged price. These, and the many other examples, each have their own pros and cons. Personally, I prefer a filter based on the actual performance of the strategy and which starts and stops the algorithm upon the crossing of the theoretical equity curve with a filtered version of itself (credit to the Zorro team for introducing me to that idea). This approach has the happy side effect of preventing catastrophic losses if the price series being traded fundamentally changes and ceases to mean revert, or at least does so for long enough to wipe out a trading account. This is a very real prospect; it is trivial to see that many price series exhibit varying periods of predominantly trending or mean reverting behaviour, however predicting the change point and using that knowledge in a practical trading strategy is certainly non-trivial. To me, it makes sense to respond to something we can know with certainty (the current performance of the strategy in real time), particularly when that knowledge is a good indicator of the breakdown of the fundamental assumptions underlying the strategy.
I have also found that, in general, reducing the lookback period of the moving average and standard deviation used in the Z-score calculation to approximately half the calculated half life of mean reversion improves performance. Reducing the lookback period further tends to result in deteriorating performance. Below is the performance for a lookback of 150, as opposed to the calculated half life of mean reversion of 311, with no rate of change filter:
The threshold parameter, which controls the operation of the filter, is an optimization parameter that may or may not hold up out of sample. There are of course numerous options for detecting so-called ‘regime change’ – in this context, when a price series transitions from having a mean-reverting character to trending – including, for example, a rolling ADF test, the Hurst exponent, even the half life of mean reversion itself, or more generally, the coefficient obtained by regressing the bar-to-bar price change against the lagged price. These, and the many other examples, each have their own pros and cons. Personally, I prefer a filter based on the actual performance of the strategy and which starts and stops the algorithm upon the crossing of the theoretical equity curve with a filtered version of itself (credit to the Zorro team for introducing me to that idea). This approach has the happy side effect of preventing catastrophic losses if the price series being traded fundamentally changes and ceases to mean revert, or at least does so for long enough to wipe out a trading account. This is a very real prospect; it is trivial to see that many price series exhibit varying periods of predominantly trending or mean reverting behaviour, however predicting the change point and using that knowledge in a practical trading strategy is certainly non-trivial. To me, it makes sense to respond to something we can know with certainty (the current performance of the strategy in real time), particularly when that knowledge is a good indicator of the breakdown of the fundamental assumptions underlying the strategy.
I have also found that, in general, reducing the lookback period of the moving average and standard deviation used in the Z-score calculation to approximately half the calculated half life of mean reversion improves performance. Reducing the lookback period further tends to result in deteriorating performance. Below is the performance for a lookback of 150, as opposed to the calculated half life of mean reversion of 311, with no rate of change filter:
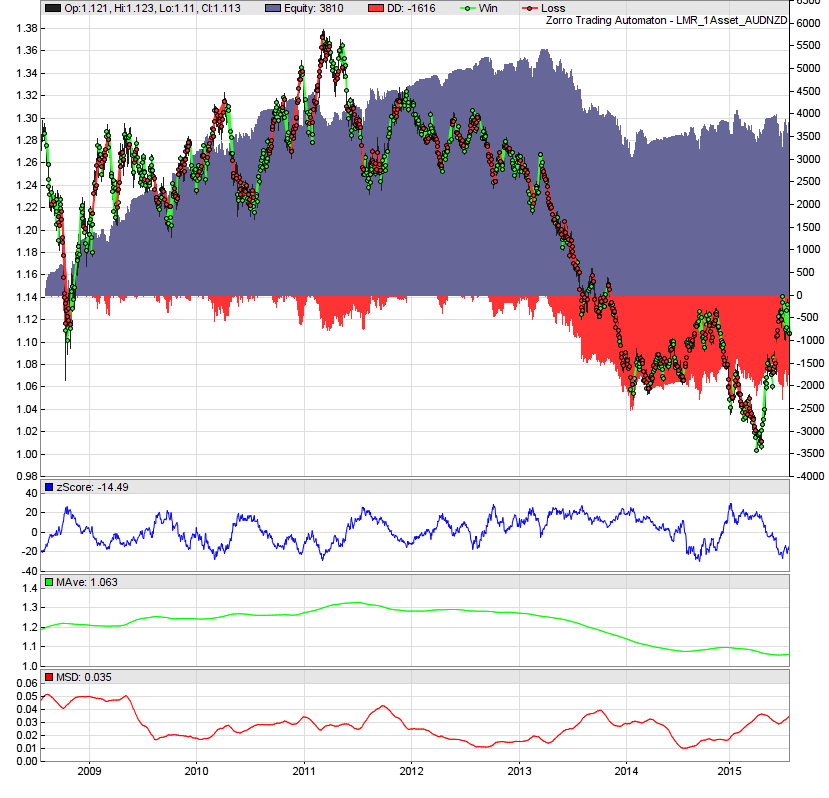 The annual return is 32% and the Sharpe ratio is 0.48. If I include transaction costs of 1.7 points per side and simulate slippage by delaying orders by ten seconds, the annual return is 25% and the Sharpe ratio is 0.4.
The annual return is 32% and the Sharpe ratio is 0.48. If I include transaction costs of 1.7 points per side and simulate slippage by delaying orders by ten seconds, the annual return is 25% and the Sharpe ratio is 0.4.
Why use statistical tests?
Chan (2013) poses the question as to why bother with statistical tests for stationarity at all when, as traders, our overriding goal is to simply determine whether a given mean reversion strategy’s performance is good enough to invest money in. Couldn’t we just run a backtest and infer all the information we need? It turns out that the statistical significance of these stationarity tests is usually far higher than that obtained through a simple backtest. The reason is that such tests make use of the data embodied in every single sample (that is, bar) of the price series. In comparison, a backtest has only the number of completed trades, which is usually far less (the linear strategy presented here is something of an exception, although it is not really a strategy that anyone intends to trade as is). In addition, most strategies’ performance is dependent on a set of parameters that are largely external to the price series itself, further confusing the idea of statistical significance (this is one reason to prefer strategies with as few external parameters as possible). On the other hand, given a price series that passed the statistical tests for stationarity, or has a sufficiently short half life of mean reversion, we can be confident that a profitable mean reversion strategy exists – possibly just not the subject of our backtest.Next steps
In the next part of this series, I’ll look into constructing artificial stationary time series and will present a more practical trading strategy for exploiting mean reversion.Files used in this post
Here you can download a zip file containing the data and source code used in this post. MeanReversionPart1References
Chan, Ernest, 2013. Algorithmic trading, John Wiley and Sons, New Jersey Kahneman, Daniel, 2011. Thinking, Fast and Slow, Farrar, Strauss and Giroux, New YorkFree Case Study:
A wantaway engineer’s journey into professional trading and out again
I went from engineering to an equity partnership at a prop trading firm to running my own systematic trading operation from home in Western Australia.
This case study is the full story – every mistake, every breakthrough, and some things I trade today.


Thanks for this very clear explanation of the use of statistical tests for calibrating mean-reversion trading strategies. It’s always nice to find an author who focuses on conveying the intuition of the models rather than the mathematics. Looking forward to part 2.
Thanks Stuart. Glad you liked the post. Part 2 should be ready in the next couple of days.
thanks for the excellent content!
i’ve traded cointegrated equity pairs for some years here with success and im now starting to work with the zorro platform.
have you been successfull when trying to import local (.csv) data to the program ?
thanks a lot
best regards
Hi Eduardo
Yes, importing CSV data into Zorro is quite simple. There is a script in the help file included with the software that allows the user to import data in CSV format.
I just started building some stat arb strategies and this post has helped a lot, thank you!
Especially that you take the concepts from E.P Chan and then translate them to R.
Glad you found the post helpful Jacques. Thanks for reading.
Hi,
Thanks for your post, it is very clear. I am working in something very similar and I would like to share with you what I am doing.
What do you think about transforming the data to make the series stationary using log differentiating operator using the R command:
> x -> diff(log(audnzd))
This commande will transform your series in a stationary process that you can check using the ADF test.
Can we apply your strategy on this new time series?
Thanks
David
Hi David, thanks for sharing your idea! If I understood you correctly, you are investigating whether we can trade a mean reversion strategy on the log returns series. Here’s some R code to take a quick look. The code will plot up the log returns series and compute the ADF test statistics, which in this case indicates that we can reject the null that the series is a random walk. The code for the vectorised backtest (just a quick and dirty one, no transaction costs included) holds a position opposite to the preceding day’s return (ie, if the preceding day showed a positive return, hold a short position the next day and vice versa). Interestingly, the plot of the cumulative returns of such a strategy seems to indicate that for a number of years, the log returns series showed a degree of anti-serial-correlation at a lag of 1, followed by a number of years of serial correlation, followed finally by a period of neither one nor the other (I can’t post the plots in the comments, but run the code and you will see what I mean). In the parlance of ‘market regimes’, to me this seems to indicate changes to the dominant regime from mean reversion to momentum to some combination of two.
########## david's idea re log differences:
y <- diff(log(audnzd))
plot(y, type = 'l', col = 'blue')
summary(ur.df(y, type = "drift", lags = 1))
# quick and dirty vectorised backtest
library(quantmod)
strat.returns <- ifelse(y > 0, Lag(y), -Lag(y))
strat.returns <- strat.returns[-1,]
plot(cumsum(strat.returns), type = "l", col = "blue")
Hi
Excellent post! specially because it shows the right way to develop strategies. I mean the use of statistics instead of crossing to SMA and adjusting parameters in many backtest until it works, And that it is actually better to spend two hours learning statistics than two hours trying to make that a strategy works. But you just not say it because everyone can say it, you actually prove it
Just a couple of questions:
Is it possible to calculate the halflife with zorro without R?
Instead of using the half life, could it be implemented as a parameter to optimize? Or could it be related to the dominant period or taken from spectral analysis? (Just thinking loud)
You mention that z>0 means a downwards reversion however in the code you write that we want to go long. Is it so because you define as: “10*(-(Close[0]” instead of “10*((Close[0]”
I also do not understand how you relate the number of open lots to the Z-score
How the actual audnzd data looks like? I am trying to make the script work by creating a cvs file from zorro. I get the data correctly into R, however I strugle trying to get just the close column for example.
I think that with the actual R bridge the half life could be calculate for a many assets in a portpolio. I wonder how the result would look like but I cant get the first step of the process to work 😛
I have extracted the audnzd data using the zorro script from the tutorial and then I have transformed the data using the R lectures into a xts object ( as far as I know ). I get around -7000 days for half life. Obviously there is something wrong.
Here is my code:
Data <- read.csv('C:/Program Files (x86)/Zorro1.44.1/Data/audnzd.csv')
timeI <- Data$Date
xtsIndex <- as.POSIXct(timeI)
xtsPrices <- xts(Data[,-1], xtsIndex)
y<-xtsPrices[,4]
Then I use that y to continue the calculation
Hi Mariano
I can’t tell if there is an error in your calculation based on the information you’ve provided. If you email me the data file and the R source code that you are using, I will take a look and get back to you. My email address is [email protected]
Terrific. I’ve read Chan’s first book, now I’m reading the second book and replicating each of his examples in Python. I’m glad I found this post because I’m a complete beginner at this stuff, despite my background in numerical techniques (aerospace engineering). I was wondering… For the simple mean reversion strategy shown above, I’ve written custom functions to open an close my positions (short or long). My code generates a list of positions, and then if it needs to sell only SOME of my positions, it searches for the positions held that will have the highest return at the current price and sells those first, in order of greatest return to smallest return. Is this correct? Otherwise I would just sell positions from the list in order, which would result in lower returns due to selling positions with lower return… Maybe I’m making this too complicated.
Additionally, I’m trying to replicate Chan’s results for this strategy… But my results don’t quite look the same. I’ve done as you have and multiplied the Zscore by 10 so that there won’t be any shares less than one. I’ve also rounded these off (so that I can get integer lot sizes). I figured this won’t have a huge impact on the strategy.
Chan’s Result:
https://drive.google.com/open?id=0B3sX68VbLqTnY054S19SWmQwSlk
My Result:
https://drive.google.com/open?id=0B3sX68VbLqTnUHhFclFkX1F2UE0
One difference, is that my P&L is measured in dollars. I’m not sure what Chan’s is in. Probably dollars too, but his losses are quite small compared to mine. The graphs are quite similar, and the only thing I think that is different is that my algo finds the lookback period to be 123 days, while his finds it to be 115 days. Not sure if this difference is enough to cause the discrepancy!
Ok nevermind. I simply changed my lookback period to be 115 days instead of 123. Huge difference. The shape of the curve is nearly the same, however now the strategy is profitable, like Chan’s, however albeit by much more.
https://drive.google.com/open?id=0B3sX68VbLqTnUkgxdmRyeXN5ODA
Interesting how the lookback has such an impact…
Hi there.. Just a question, isn’t lag(x, – 1) == looking into t+1?
Best Regards
Thank you very much. I’m just starting to read Chan’s first book, and learning Zorro and R.
This is so helpful and the way you explained it make so much sense.
Keep it coming.
Thanks Nat, really glad you like reading it as much as I love writing about it!
Hi there, I just posted a comment as a reply to another reader, unintentionally.
I just wanted to point out that the lag function should have a positive integer as the Number of Lags you would like to input in the series, not a negative one (-1) as, in my opinion, would make a lot more sense, even though I haven’t wrote any R functions or scripts ..
Best Regards
I agree with this comment. Can anyone else confirm please?
Hi Eduardo, David – my apologies for not answering this one sooner. Eduardo is correct, lag() requires a positive integer for the intended purpose here. I’ll have to update this post when I find some time!
Cheers
Kris
Hi Kris
Quantopian today has announced they are not supporting their API brokerage connections any more.
I am now studying Zorro Trader. I typically use R for my research and im wondering if you maybe can point me in the direction of a zorro code example that hooks up to IB?
My main question is:
Can i check for open positions, pattern day trade rules etc etc within zorro and talk to IB if you will?
Looking for an example to do that! Let me know! Thanks
Andrew
Well that’s interesting. I hope that news broadens the Zorro user base a little more!
It’s super easy to hook up to IB with Zorro. There’s a plugin that enables Zorro to talk to IB – both via TWS and the Gateway (the latter of which is more stable and consumes fewer compute resources). All you need to do is launch either TWS or the Gateway, sign in, then launch Zorro, select ‘IB’ from the account dropdown, and click Trade. There are one or two other tricks to making it work: for instance, if you are connecting via TWS, you need to set the socket port to 7496 (in your TWS, that’s under Configuration->API->Settings). For the Gateway, its 4002. There’s also a ‘Read Only API’ option that you need to deselect in order to actually send trades to market.
Trading with IB has a few nuances, like subscribing to the correct data feed and ensuring your symbology matches theirs. But if you’re already trading with IB, I assume you’re across those issues already.
Maybe a more detailed demonstration could be a blog post? If there’s demand for that, please let me know!