
Quant trading
Resourcing a Triangulated Stat Arb Operation as a Solo Trader
Part 6 of 6: Statistical Arbitrage for Independent Traders Previously: At its simplest, stat arb is a bet on convergence:
Part 6 of 6: Statistical Arbitrage for Independent Traders Previously: At its simplest, stat arb is a bet on convergence:

Part 5 of 6: Statistical Arbitrage for Independent Traders Previously: Last time, I showed you a pattern in energy spreads

From Pairs to Portfolio Part 4 of 6: Statistical Arbitrage for Independent Traders Previously: Pairs trading remains a feasible approach

Why the path to making money in trading runs through work you’d better find interesting Data mining and vibe quanting

Someone asked me recently whether strategies based on mean reversion, trend following, and momentum are “good” or just data mining.

My last two articles on AI and trading research got more engagement than almost anything I’ve written. “More of the
(Most of Them Will Lose Money) AI makes it easier than ever to build trading strategies. Prompt a model, run

This week I discovered the “vibe quant” movement (or rather, it discovered me). People using LLMs to find trading strategies,

The four hats of the solo trader At a trading firm or fund, the researcher doesn’t run the execution desk.

Part 3 of a series on Statistical Arbitrage for Independent Traders Previously: In the last article, we built up a
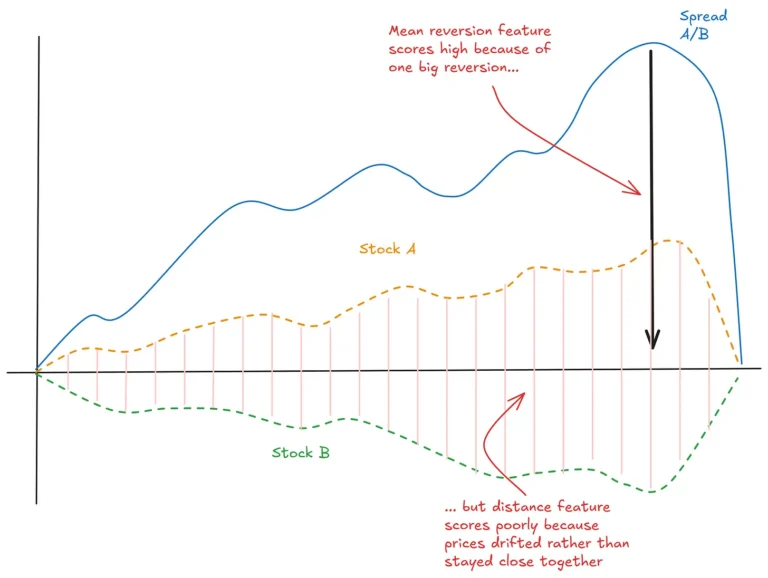
Previously: A Tale of Two Prices (the core idea of stat arb) Last time we established that stat arb is
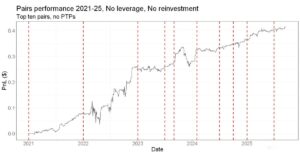
Part 1 of a series on Statistical Arbitrage for Independent Traders. It was the age of wisdom, it was the