
Quant trading
When Is a Mispricing Not a Mispricing?
Part 5 of 6: Statistical Arbitrage for Independent Traders Previously: Last time, I showed you a pattern in energy spreads
Part 5 of 6: Statistical Arbitrage for Independent Traders Previously: Last time, I showed you a pattern in energy spreads

From Pairs to Portfolio Part 4 of 6: Statistical Arbitrage for Independent Traders Previously: Pairs trading remains a feasible approach
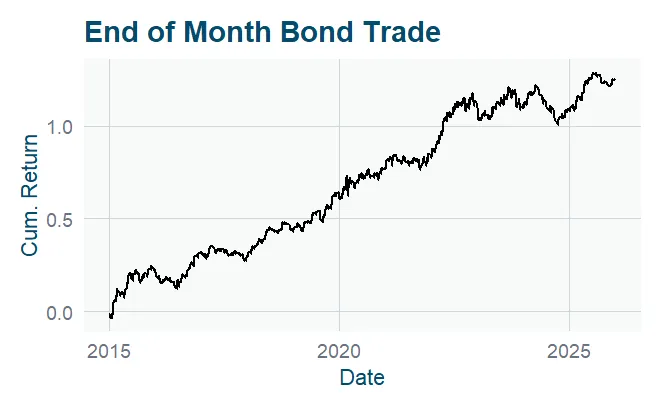
What’s Past is Prologue Let’s be honest: 2025 was a pretty good year to be a systematic trader. If you
We’ve all used on/off type trading signals at some point. But you can nearly always extract more insight with a

The best trading edges are often found in places most people don’t think to look. It’s why being a bit

Someone recently asked me if I have a checklist for adopting new trading strategies. You know, a neat little formula
UVXY is an ETF that targets 1.5x the daily returns of a 30-day constant-maturity position in VX futures – the
In 2021, James, I, and a small team decided to set up a crypto trading venture. We faced several problems,
In Australia, if you’re serious about getting the job done effectively and efficiently, you might say: “I’m not here to

You rarely meet a rich forex trader. I’ve met plenty of rich traders who trade quant factors or stat arb.

Here’s a chart of long-term asset performance…. The blue line shows returns from US stocks from 1900 to today.

Anyone that’s been around the markets knows that the monthly release of the United States Department of Labor’s Non-Farm Payrolls