
DataRTime series modelling
A Simple Trick for Dealing with Overlapping Data
Last week, we looked at simple data analysis techniques to test for persistence. But we only looked at a feature
Last week, we looked at simple data analysis techniques to test for persistence. But we only looked at a feature

Towards the end of last year, we ran a couple of free Zoom webinars on: Here are the recordings: Basics
dplyr 1.1.0 was a significant release that makes several common data operations more syntactically intuitive. The most significant changes relate

Holding data in a tidy format works wonders for one’s productivity. Here we will explore the tidyr package, which is

When data is too big to fit into memory, one approach is to break it into smaller pieces, operate on

When you’re working with large universes of stock data you’ll come across a lot of challenges: Stocks pay dividends and

Recently, we wrote about calculating mean rolling pairwise correlations between the constituent stocks of an ETF. The tidyverse tools dplyr

Working with modern APIs you will often have to wrangle with data in JSON format. This article presents some tools

How might we calculate rolling correlations between constituents of an ETF, given a dataframe of prices? For problems like this,
In this post, we’re going to show how a quant trader can manipulate stock price data using the dplyr R

In this post, we are going to construct snapshots of historic S&P 500 index constituents, from freely available data on
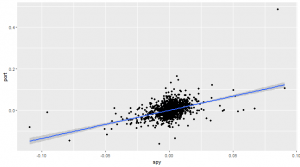
There are 2 good reasons to buy put options: because you think they are cheap because you want downside protection.