CryptoData analysisThink like a trader
Trading Signals in High Definition
We’ve all used on/off type trading signals at some point. But you can nearly always extract more insight with a
We’ve all used on/off type trading signals at some point. But you can nearly always extract more insight with a
UVXY is an ETF that targets 1.5x the daily returns of a 30-day constant-maturity position in VX futures – the

Last week, we looked at simple data analysis techniques to test for persistence. But we only looked at a feature
An assumption we often make in trading research is that the future will be at least a little like the
When you do anything with data, you should think about the intuition of each thing you do, and what it

This post presents an analysis of the SPY returns process using the QuantConnect research platform. QuantConnect is a strategy development

Holding data in a tidy format works wonders for one’s productivity. Here we will explore the tidyr package, which is

If you want to make money trading, you’re going to need a way to identify when an asset is likely
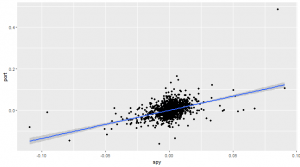
There are 2 good reasons to buy put options: because you think they are cheap because you want downside protection.
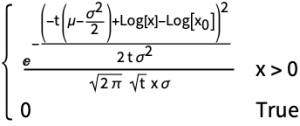
We’ve been working on visualisation tools to make option pricing models intuitive to the non-mathematician. Fundamental to such an exercise