Deep Learning for Trading Part 4: Fighting Overfitting is the fourth in a multi-part series in which we explore and compare various deep learning tools and techniques for market forecasting using Keras and TensorFlow. In Deep Learning for Trading Part 1, we introduced Keras and discussed some of the major obstacles to using deep learning techniques in trading systems, including a warning about attempting to extract meaningful signals from historical market data. If you haven’t read that article, it is highly recommended that you do so before proceeding, as the context it provides is important. Part 2 provides a walk-through of setting up Keras and Tensorflow for R using either the default CPU-based configuration, or the more complex and involved (but well worth it) GPU-based configuration under the Windows environment. Part 3 is an introduction to the model building, training and evaluation process in Keras. We train a simple feed forward network to predict the direction of a foreign exchange market over a time horizon of one hour and assess its performance..In the last post, we trained a densely connected feed-forward neural network to forecast the direction of the EUR/USD exchange rate over a time horizon of one hour. We landed on a model that predicted slightly better than random on out of sample data. We also saw in our learning plots that our network exhibited overfitting pretty badly at around 40 epochs. In this post, I’m going to demonstrate some tools to help fight overfitting and push your models further. Let’s get started!
Regularization
Regularization is a commonly used technique to mitigate overfitting of machine learning models, and it can also be applied to deep learning. Regularization essentially constrains the complexity of a network by penalizing larger weights during the training process. That is, by adding a term to the loss function that grows as the weights increase. Keras implements two common types of regularization:- L1, where the additional cost is proportional to the absolute value of the weight coefficients
- L2, where the additional cost is proportional to the square of the weight coefficients
Getting smarter with our learning rate
When we add regularization to a network, we might find that we need to train it for more epochs in order to reach convergence. This implies that the network might benefit from a higher learning rate during early stages of model training.1 However, we also know that sometimes a network can benefit from a smaller learning rate at later stages of the training process. Think of it like the model’s loss being stuck halfway down the global minimum, bouncing from one side of the loss surface to the other with each weight update. By reducing the learning rate, we can make the subsequent weight updates less dramatic, which enables the loss to ‘fall’ further down towards the true global minimum. By using another Keras callback, we can automatically adjust our learning rate downwards when training reaches a plateau:reduce_lr <- callback_reduce_lr_on_plateau(monitor = "val_acc", factor = 0.9,
patience = 10, verbose = 1, mode = "auto",
epsilon = 0.005, min_lr = 0.00001)
This tells Keras to reduce the learning rate by a factor of 0.9 whenever validation accuracy doesn’t improve for patience epochs. Also note the epsilon parameter, which controls the threshold for measuring the new optimum. Setting this to a higher value results in fewer changes to the learning rate. This parameter should be on a scale that is relevant to the metric being tracked, validation accuracy in this case.
Putting it together
Here’s the code for an L2 regularized feed forward network with both reduce_lr_on_plateau and model_checkpoint callbacks (data import and processing is the same as in Deep Learning for Trading: Part 3):###### FFN with weight regularization #####
model.reg <- keras_model_sequential()
model.reg %>%
layer_dense(units = 150, kernel_regularizer = regularizer_l2(0.001), activation = 'relu', input_shape = ncol(X_train)) %>%
layer_dense(units = 150, kernel_regularizer = regularizer_l2(0.001), activation = 'relu') %>%
layer_dense(units = 150, kernel_regularizer = regularizer_l2(0.001), activation = 'relu') %>%
layer_dense(units = 1, activation = 'sigmoid')
summary(model.reg)
model.reg %>% compile(
loss = 'binary_crossentropy',
optimizer = optimizer_rmsprop(lr=0.001),
metrics = c('accuracy')
)
filepath <- "C:/Users/Kris/Research/DeepLearningForTrading/model_reg.hdf5" # set up your own filepath
checkpoint <- callback_model_checkpoint(filepath = filepath, monitor = "val_acc", verbose = 1,
save_best_only = TRUE,
save_weights_only = FALSE, mode = "auto")
reduce_lr <- callback_reduce_lr_on_plateau(monitor = "val_acc", factor = 0.9,
patience = 20, verbose = 1, mode = "auto",
epsilon = 0.005, min_lr = 0.00001)
history.reg <- model.reg %>% fit(
X_train, Y_train,
epochs = 100, batch_size = nrow(X_train),
validation_data = list(X_val, Y_val), shuffle = TRUE,
callbacks = list(checkpoint, reduce_lr)
)
# plot training loss and accuracy
plot(history.reg)
max(history.reg$metrics$val_acc)
# load and evaluate best model
rm(model.reg)
model.reg <- keras:::keras$models$load_model(filepath)
model.reg %>% evaluate(X_test, Y_test)
Plotting the training curves now gives us three plots – loss, accuracy and learning rate:
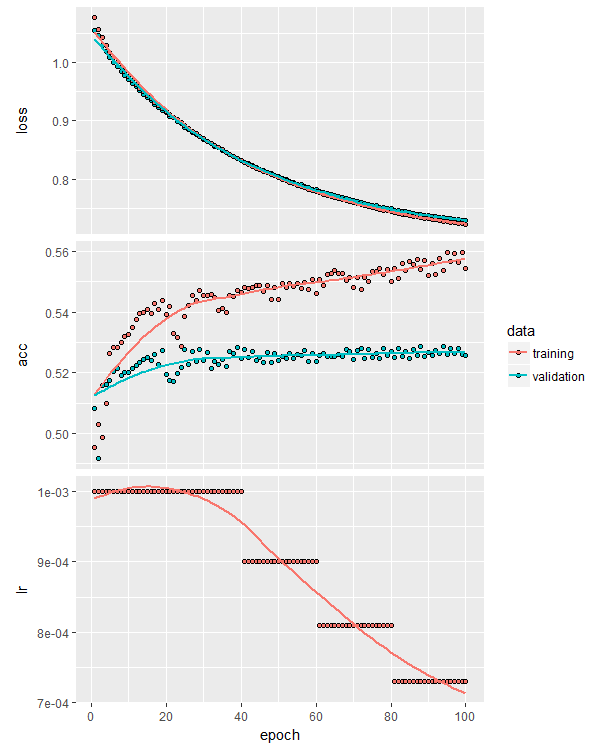 This particular training process resulted in an out of sample accuracy of 53.4%, slightly better than our original unregularized model. You can experiment with more or less regularization, as well as applying regularization to the bias terms and layer outputs.
This particular training process resulted in an out of sample accuracy of 53.4%, slightly better than our original unregularized model. You can experiment with more or less regularization, as well as applying regularization to the bias terms and layer outputs.
Dropout
Dropout is another commonly used tool to fight overfitting. Whereas regularization is used throughout the machine learning ecosystem, dropout is specific to neural networks. Dropout is the random zeroing (“dropping out”) of some proportion of a layer’s outputs during training. The theory is that this helps prevents pairs or groups of nodes from learning random relationships that just happen to reduce the network loss on the training set (that is, result in overfitting). Hinton and his colleagues, the discoverers of dropout, showed that it is generally superior to other forms of regularization and improves model performance on a variety of tasks. Read the original paper here.2 Dropout is implemented in Keras as its own layer, layer_dropout(), which applies dropout on its inputs (that is, on the outputs of the previous layer in the stack). We need to supply the fraction of outputs to drop out, which we pass via the rate parameter. In practice, dropout rates between 0.2 and 0.5 are common, but the optimal values for a particular problem and network configuration need to be determined through appropriate cross validation. At the risk of getting ahead of ourselves, when applying dropout to recurrent architectures (which we’ll explore in a future post), we need to apply the same pattern of dropout at every timestep, otherwise dropout tends to hinder performance rather than enhance it.3 Here’s an example of how we build a feed-forward network with dropout in Keras:###### FFN with dropout #####
model.drop <- keras_model_sequential()
model.drop %>%
layer_dense(units = 150, activation = 'relu', input_shape = ncol(X_train)) %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 150, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 150, activation = 'relu') %>%
layer_dropout(rate = 0.3) %>%
layer_dense(units = 1, activation = 'sigmoid')
summary(model.drop)
model.drop %>% compile(
loss = 'binary_crossentropy',
optimizer = optimizer_rmsprop(lr=0.001),
metrics = c('accuracy')
)
filepath <- "C:/Users/Kris/Research/DeepLearningForTrading/model_drop.hdf5" # set up your own filepath
checkpoint <- callback_model_checkpoint(filepath = filepath, monitor = "val_acc", verbose = 1,
save_best_only = TRUE,
save_weights_only = FALSE, mode = "auto")
reduce_lr <- callback_reduce_lr_on_plateau(monitor = "val_acc", factor = 0.9,
patience = 20, verbose = 1, mode = "auto",
epsilon = 0.005, min_lr = 0.00001)
history.drop <- model.drop %>% fit(
X_train, Y_train,
epochs = 150, batch_size = nrow(X_train),
validation_data = list(X_val, Y_val), shuffle = TRUE,
callbacks = list(checkpoint, reduce_lr)
)
# plot training loss and accuracy
plot(history.drop)
max(history.drop$metrics$val_acc)
# load and evaluate best model
rm(model.drop)
model.drop <- keras:::keras$models$load_model(filepath)
model.drop %>% evaluate(X_test, Y_test)
Training the model using the same procedure as we used in the L2-regularized model above, including the reduce learning rate callback, we get the following training curves:
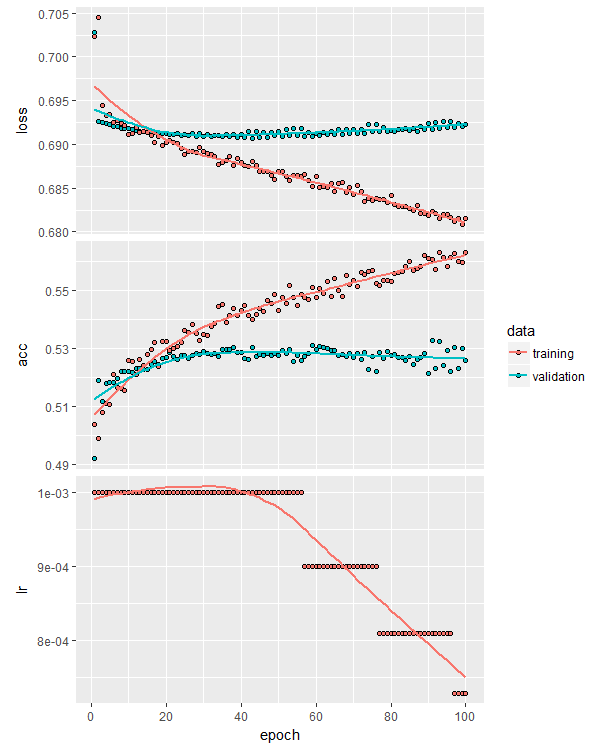 One of the reasons dropout is so useful is that it enables the training of larger networks by reducing the likelihood of overfitting. Here’s the training curves for a similar model but this time eight layers deep:
One of the reasons dropout is so useful is that it enables the training of larger networks by reducing the likelihood of overfitting. Here’s the training curves for a similar model but this time eight layers deep:
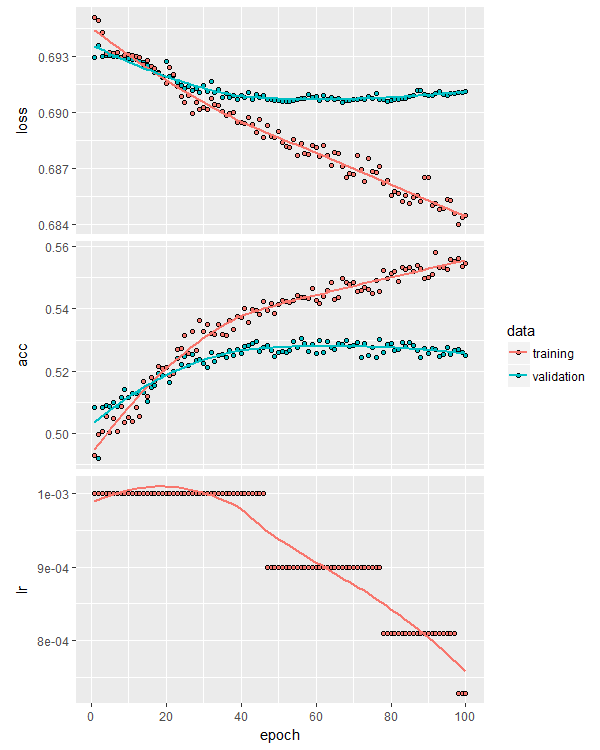 Notice that overfitting isn’t significantly worse than the shallower model. Also notice that it didn’t really learn any new, independent relationships from the data – this is evidenced by the failure to beat the previous model’s validation accuracy. Perhaps 53% is the upper out of sample accuracy limit for this data set and this approach to modeling it.
With dropout, you can also afford to use a larger learning rate, which means it is a good idea to make use of the reduce_lr_on_plateau callback and kick off training with a higher learning rate, which can always be decayed as learning stalls.
Finally, one important consideration when using dropout is constraining the size of the network weights, particularly when a large learning rate is used early in training. In the Hinton et. al. paper linked above, constraining the weights was shown to improve performance in the presence of dropout.
Keras makes that easy thanks to the kernel_constraint parameter of layer_dense() :
Notice that overfitting isn’t significantly worse than the shallower model. Also notice that it didn’t really learn any new, independent relationships from the data – this is evidenced by the failure to beat the previous model’s validation accuracy. Perhaps 53% is the upper out of sample accuracy limit for this data set and this approach to modeling it.
With dropout, you can also afford to use a larger learning rate, which means it is a good idea to make use of the reduce_lr_on_plateau callback and kick off training with a higher learning rate, which can always be decayed as learning stalls.
Finally, one important consideration when using dropout is constraining the size of the network weights, particularly when a large learning rate is used early in training. In the Hinton et. al. paper linked above, constraining the weights was shown to improve performance in the presence of dropout.
Keras makes that easy thanks to the kernel_constraint parameter of layer_dense() :
max_weight_constraint <- 5 model.drop <- keras_model_sequential() model.drop %>% layer_dense(units = 150, activation = 'relu', kernel_constraint = constraint_maxnorm(max_value = max_weight_constraint), input_shape = ncol(X_train)) %>% layer_dropout(rate = 0.3) %>% layer_dense(units = 150, activation = 'relu', kernel_constraint = constraint_maxnorm(max_value = max_weight_constraint)) %>% layer_dropout(rate = 0.3) %>% layer_dense(units = 150, activation = 'relu', kernel_constraint = constraint_maxnorm(max_value = max_weight_constraint)) %>% layer_dropout(rate = 0.3) %>% layer_dense(units = 1, activation = 'sigmoid')This model provided an ever-so-slight bump in validation accuracy:
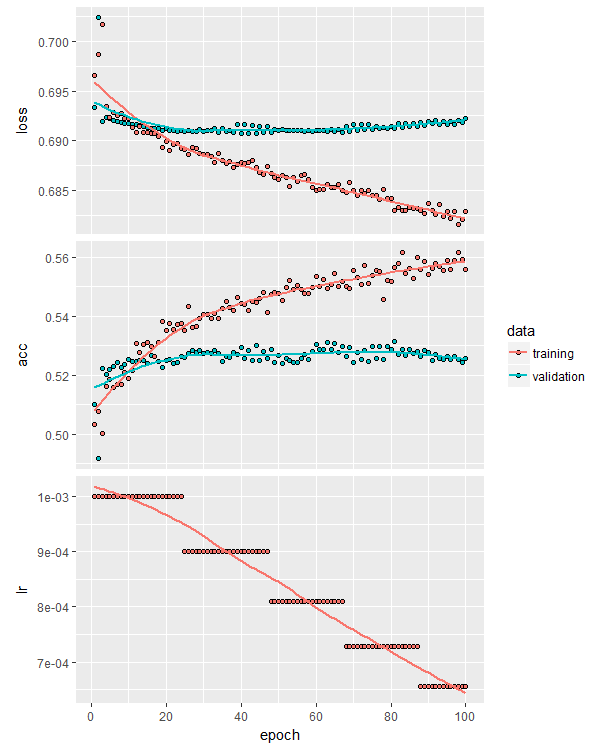 And quite a stunning test-set equity curve:
And quite a stunning test-set equity curve:
# get predictions on test set and plot simple, frictionless PnL preds <- model.drop %>% predict_proba(X_test) threshold <- 0.5 trades <- ifelse(preds >= threshold, Y_test_raw, ifelse(preds <= 1-threshold, -Y_test_raw, 0)) plot(cumsum(trades), type='l')
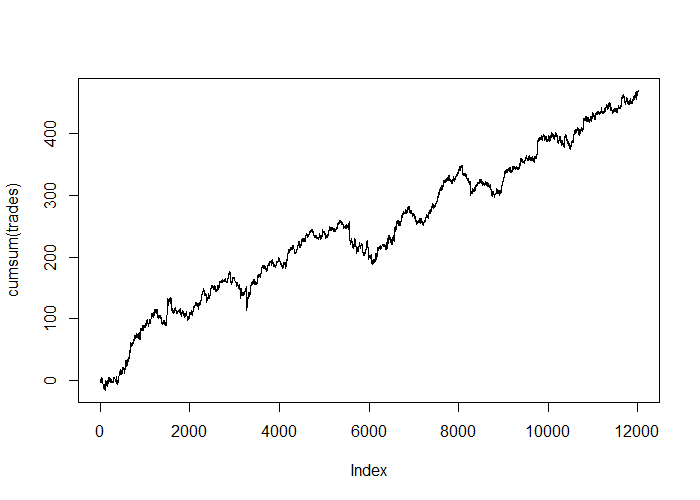 Interestingly, every experiment I performed in writing this post resulted in a positive out of sample equity curve. The results were all slightly different, even when using the same model setup, which reflects the non-deterministic nature of the training process (two identical networks trained on the same data can result in different weights, depending on the initial, pre-training weights of each network). Some equity curves were better than others, but they were all positive.
Here are some examples:
Interestingly, every experiment I performed in writing this post resulted in a positive out of sample equity curve. The results were all slightly different, even when using the same model setup, which reflects the non-deterministic nature of the training process (two identical networks trained on the same data can result in different weights, depending on the initial, pre-training weights of each network). Some equity curves were better than others, but they were all positive.
Here are some examples:
With L2-weight regularization and no dropout:
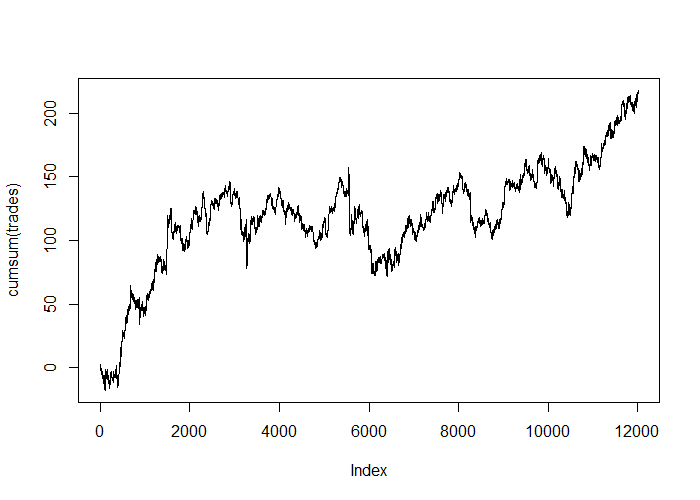
With a dropout rate of 0.2 applied at each layer, no regularization, and no weight constraints:
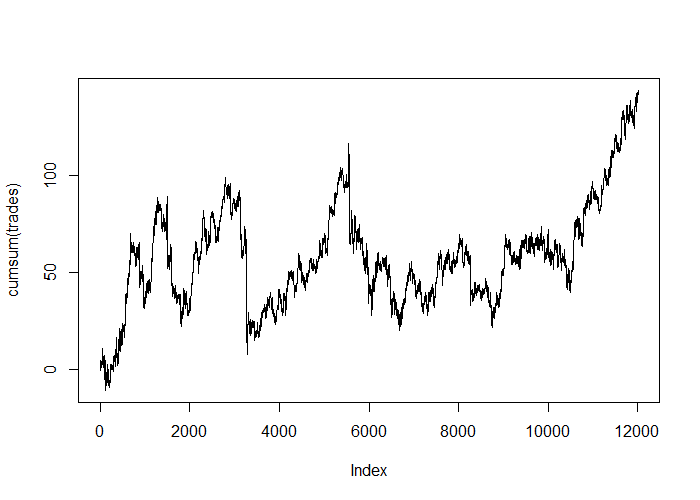 Of course, as mentioned in the last post, the edge of these models disappears when we apply retail spreads and broker commissions, but the frictionless equity curves demonstrate that deep learning, even using a simple feed-forward architecture, can extract predictive information from historical price action, at least for this particular data set, and that tools like regularization and dropout can make a difference to the quality of the model’s predictions.
Of course, as mentioned in the last post, the edge of these models disappears when we apply retail spreads and broker commissions, but the frictionless equity curves demonstrate that deep learning, even using a simple feed-forward architecture, can extract predictive information from historical price action, at least for this particular data set, and that tools like regularization and dropout can make a difference to the quality of the model’s predictions.
What’s next?
Before we get into advanced model architectures, in the next unit I’ll show you:- One of the more cutting edge architectures to get the most out of a densely connected feed forward network.
- How to interrogate and visualize the training process in real-time.
Conclusions
This post demonstrated how to fight overfitting with regularization and dropout using Keras’ sequential model paradigm. While we further refined our previously identified slim edge in predicting the EUR/USD exchange rate’s direction, in practical terms, traders with access to retail spreads and commission will want to consider longer holding times to generate more profit per trade, or will need a more performant model to make money with this approach.Free Case Study:
A wantaway engineer’s journey into professional trading and out again
I went from engineering to an equity partnership at a prop trading firm to running my own systematic trading operation from home in Western Australia.
This case study is the full story – every mistake, every breakthrough, and some things I trade today.



Great post and much appreciated.. do you happen to have the actual original data you used before it was processed with the data gen regularization algo?
thx, bl
Hi Brian, I do have that data, however it is in Zorro’s binary .bar file format. Do you use Zorro? If not, I can always convert it to CSV and upload it?
I don’t have Zorro, i can download it from them if that is easier. i was looking at the C file you used to generate the scaler on the data, if its not too much trouble CSV would be a little easier for me otherwise i can just pick up Zorro.
thx for that,
brian
Hi Brian,
Sorry for the slow response, but I’ve uploaded the raw EUR/USD data (as CSV) used in this post to the download archive linked above. It’s hourly data covering the period 2010-01-01 to 2017-12-01 from FXCM.