
Autoregressive Models 101
An autoregressive (AR) model is a time-series multiple regression where:- the predictors are past values of the time series
- the target is the next realisation of the time series
Ernie’s AR Model
Ernie says that“Time-series techniques are most useful in markets where fundamental information and intuition are either lacking or not particularly useful for short-term predictions. Currencies … fit this bill.”He built an \(AR(p)\) model for AUD/USD minutely prices (spot, I assume), using Bayesian Information Criterion to find the optimal \(p\). He used data from July 24 2007 to August 12 2014 to find \(p\) and the model coefficients:
 He used an out-of-sample data set from August 12 2014 to August 3 2015 to generate the following (pre-cost) backtest:
He used an out-of-sample data set from August 12 2014 to August 3 2015 to generate the following (pre-cost) backtest:

Thinking deeper about the model
If we were to use an \(AR(p)\) model of prices to predict future prices, what are we assuming? Essentially, that past prices are correlated with future prices, to the extent that they contain tradable information. The first part of that seems perfectly reasonable. After all, a very good place to start predicting tomorrow’s price would be today’s price. The latter part of that however is fairly heroic. Such a naive forecast is obviously not going to help much when it comes to making profitable trades. If we could forecast returns on the other hand…now that would be a useful thing! Most quants will tell you that price levels can’t contain information that is predictive in a useful way, and that instead, you need to focus on the process that manifests those prices – namely, returns. Building a time series model on prices feels a bit like doing technical analysis… albeit with a more interesting tool than a trend line. Anyway, let’s put that aside for now and dig in. If we’re going to use an AR model, then a reasonable place to start would be figuring out if we have an AR process. For that, we can use theacffunction in R:
 Our minutely price series is indeed very strongly autocorrelated, as we’d expect. We have a lot of data (I used minutely data from 2009 – 2020), and of course, the price from one minute ago looks a lot like the price right now.
We can use the partial autocorrelation function (
Our minutely price series is indeed very strongly autocorrelated, as we’d expect. We have a lot of data (I used minutely data from 2009 – 2020), and of course, the price from one minute ago looks a lot like the price right now.
We can use the partial autocorrelation function (pacf) to get a handle on how many lags we might need to build an AR model.
A partial autocorrelation is the correlation of a variable and a lagged version of itself that isn’t explained by correlations of previous lags. Essentially, it prevents information explained by prior lags from leaking into subsequent lags.
That makes it a useful way to identify the number of lags to use in your AR model – if there is a significant partial correlation at a lag, then that lag has some explanatory power over your variable and should be included. Indeed, you find that the partial correlation values correspond to the coefficients of the AR model.
Here are the partial autocorrelations with the lag-0 correlation removed:
 This is interesting. If our price data were a random walk, we’d expect no lags of the PACF plot to be significant. Here, we have many lags having significant autocorrelation – is our price series weakly stationary, or does it drift?
Here’s a random walk simulation and the resulting PACF plot for comparison:
This is interesting. If our price data were a random walk, we’d expect no lags of the PACF plot to be significant. Here, we have many lags having significant autocorrelation – is our price series weakly stationary, or does it drift?
Here’s a random walk simulation and the resulting PACF plot for comparison:
# random walk for comparison
n <- 10000
random_walk <- cumsum(c(100, rnorm(n)))
data.frame(x = 1:(n+1), y = random_walk) %>%
ggplot(aes(x = x, y = y)) +
geom_line() +
theme_bw()
p <- pacf(random_walk, plot = FALSE)
plot(p[2:20])
Here’s a plot of the random walk:
 And the PACF plot (again, with the lag-0 correlation removed):
And the PACF plot (again, with the lag-0 correlation removed):
 Returning to the PACF plot of our price data, Ernie’s choice of 10 lags for his AR model looks reasonable (those partial correlation values translate to the coefficients of the AR model), but the data also suggests that going as far back as 15 lags is OK too.
It would be interesting to see how that PACF plot changes through time. Here it is separately for each year in our data set:
Returning to the PACF plot of our price data, Ernie’s choice of 10 lags for his AR model looks reasonable (those partial correlation values translate to the coefficients of the AR model), but the data also suggests that going as far back as 15 lags is OK too.
It would be interesting to see how that PACF plot changes through time. Here it is separately for each year in our data set:
# annual pacfs
annual_partials <- audusd %>%
mutate(year = year(timestamp)) %>%
group_by(year) %>%
# create a column of date-close dataframes called data
nest(-year) %>%
mutate(
# calculate acf for each date-close dataframe in data column
pacf_res = purrr::map(data, ~ pacf(.x$close, plot = F)),
# extract acf values from pacf_res object and drop redundant dimensions of returned lists
pacf_vals = purrr::map(pacf_res, ~ drop(.x$acf))
) %>%
# promote the column of lists such that we have one row per lag per year
unnest(pacf_vals) %>%
group_by(year) %>%
mutate(lag = seq(0, n() - 1))
signif <- function(x) {
qnorm((1 + 0.95)/2)/sqrt(sum(!is.na(x)))
}
signif_levels <- audusd %>%
mutate(year = year(timestamp)) %>%
group_by(year) %>%
summarise(significance = signif(close))
annual_partials %>%
filter(lag > 0, lag <= 20) %>%
ggplot(aes(x = lag, y = pacf_vals)) +
geom_segment(aes(xend = lag, yend = 0)) +
geom_point(size = 1, colour = "steelblue") +
geom_hline(yintercept = 0) +
facet_wrap(~year, ncol = 3) +
geom_hline(data = signif_levels, aes(yintercept = significance), colour = 'red', linetype = 'dashed')
 Those partial correlations do look quite stable… But remember, we’re not seeing any information about returns here – we’re only seeing that recent prices are correlated with past prices.
My gut feel is that this represents the noisy mean reversion you tend to see in FX at short time scales. Take a look at this ACF plot of minutely returns (not prices):
Those partial correlations do look quite stable… But remember, we’re not seeing any information about returns here – we’re only seeing that recent prices are correlated with past prices.
My gut feel is that this represents the noisy mean reversion you tend to see in FX at short time scales. Take a look at this ACF plot of minutely returns (not prices):
ret_acf <- acf(audusd %>%
mutate(returns = (close - dplyr::lag(close))/dplyr::lag(close)) %>%
select(returns) %>%
na.omit() %>%
pull(),
lags = 20, plot = FALSE
)
plot(ret_acf[2:20], main = 'ACF of minutely returns')
 There are clearly some significant negative autocorrelations when we view things through the lens of returns. Any method of trading that negative autocorrelation would show results like Ernie’s backtest – including AR models and dumber-seeming technical analysis approaches. At least, in a world without transaction costs.
I think we can make the following assumptions:
There are clearly some significant negative autocorrelations when we view things through the lens of returns. Any method of trading that negative autocorrelation would show results like Ernie’s backtest – including AR models and dumber-seeming technical analysis approaches. At least, in a world without transaction costs.
I think we can make the following assumptions:
- There is nothing special about the last ten minutely prices
- This is not going to be something we can trade, particularly under retail spot FX trading conditions.
- Fit an \(AR(10)\) model on a big chunk of data
- Simulate a trading strategy that uses that model for its predictions on unseen data
timestamp):
# fit an AR model ar <- arima( audusd %>% filter(timestamp < "2014-01-01") %>% select(close) %>% pull(), order = c(10, 0, 0) )Here we use the
arima function from the stats package and specify an order of (10, 0, 0). Those numbers correspond to the number of autoregressive terms, the degree of differencing, and the number of moving average terms, respectively. Specifying zero for the latter two results in an AR model.
Here are the model coefficients:
ar$coef # ar1 ar2 ar3 ar4 ar5 ar6 ar7 ar8 ar9 ar10 # 0.9741941564 0.0228922865 0.0019821879 -0.0073977641 0.0045880720 0.0072364966 -0.0047513598 0.0003852733 -0.0048944003 0.0057283039 # intercept # 0.6692288336Next, here’s an R function for generating predictions from an AR model:
# fit an AR model and return the step-ahead prediction
# can fit a new model or return predictions given an existing set of coeffs and new data
# params:
# series: data to use to fit model or to predict on
# fixed: either NA or a vector of coeffs of same length as number of model parameters
# usage:
# fit a new model an return next prediction: series should consist of the data to be fitted, fixed should be NA
# fit_ar_predict(audusd$close[1:100000], order = c(10, 0, 0))
# predict using an existing set of coeffs: series and fixed should be same length as number of model parameters
# fit_ar_predict(audusd$close[100001:100010], order = c(10, 0, 0), fixed = ar$coef)
fit_ar_predict <- function(series, order = 10, fixed = NA) {
if(sum(is.na(fixed)) == 0) {
# make predictions using static coefficients
# arima(series, c(1, 0, 0)) fits an AR(1)
predict(arima(series, order = c(order, 0, 0), fixed = fixed), 1)$pred[1]
} else {
# fit a new model
predict(arima(series, order = c(order, 0, 0)), 1)$pred[1]
}
}
If you supply the fixed parameter (corresponding to the model coefficients), the function returns the step-ahead prediction given the values in series. The length of series needs to be the same asorder, and the length of fixed needs to be order + 1 to account for the intercept term.
If you don’t supply the fixed parameter, the function will fit an \(AR(order)\) model on the data in series and return the step-ahead prediction.
Save this file in Zorro’s Strategy folder.
Finally, here’s the Zorro code for running the simulation given our model parameters derived above (no transaction costs):
#include <r.h>
function run()
{
set(PLOTNOW);
setf(PlotMode, PL_FINE);
StartDate = 2014;
EndDate = 2015;
BarPeriod = 10;
LookBack = 10;
MaxLong = MaxShort = 1;
MonteCarlo = 0;
if(is(INITRUN))
{
// start R and source the kalman iterator function
if(!Rstart("ar.R", 2))
{
print("Error - can't start R session!");
quit();
}
}
asset("AUD/USD");
Spread = Commission = RollLong = RollShort = Slippage = 0;
// generate reverse price series (the order of Zorro series is opposite what you'd expect)
vars closes = rev(series(priceClose()));
// model parameters
int order = 10;
var coeffs[11] = {0.9793975109, 0.0095665978, 0.0025503174, 0.0013394797, 0.0060263045, -0.0023060104, -0.0022220192, 0.0006940781, 0.0011942208, 0.0037558386, 0.9509437891}; //note 1 extra coeff - intercept
if(!is(LOOKBACK)) {
// send function argument values to R
Rset("order", order);
Rset("series", closes, order);
Rset("fixed", coeffs, order+1);
// compute AR prediction and trade
var pred = Rd("fit_ar_predict(series = series, order = order, fixed = fixed)");
printf("\nCurrent: %.5f\nPrediction: %.5f", priceClose(), pred);
if(pred > priceClose())
enterLong();
else if(pred < priceClose())
enterShort();
}
}
Now, since we’re calling out to R once every minute for a new prediction, this simulation is going to take a while. Let’s just run it for a couple of years out of sample while we go make a cocktail…
Here’s the result:
 Which is quite consistent with Ernie’s pre-cost backtest (noting differences due to slightly different historical data periods and modeling software. Also note that Zorro’s percent return calculation is based on the assumption that you invest the minimum amount in order to avoid a margin call in the backtest – hence why it looks astronomically large in this case).
Unfortunately, this is a massively hyperactive strategy that is going to get killed by costs. You can see in the Zorro backtest that the average pre-cost profit per trade is only 0.1 pip. That’s going to make your FX broker extremely pleased.
Which is quite consistent with Ernie’s pre-cost backtest (noting differences due to slightly different historical data periods and modeling software. Also note that Zorro’s percent return calculation is based on the assumption that you invest the minimum amount in order to avoid a margin call in the backtest – hence why it looks astronomically large in this case).
Unfortunately, this is a massively hyperactive strategy that is going to get killed by costs. You can see in the Zorro backtest that the average pre-cost profit per trade is only 0.1 pip. That’s going to make your FX broker extremely pleased.
Is there something we can trade here?
Transaction costs are a major problem, so let’s start there. If we saw evidence of partial autocorrelation at longer time horizons, we could potentially slow the strategy down such that it traded less frequently and held on to positions for longer. Here are some rough PACF charts of what that might look like. First, using ten-minutely data:# 10-minute partials
partial <- pacf(
audusd %>%
mutate(minute = minute(timestamp)) %>%
filter(minute %% 10 == 0) %>%
select(close) %>%
pull(),
lags = 20, plot = FALSE)
plot(partial[2:20], main = 'Ten minutely PACF')
 Next, hourly:
Next, hourly:
# hourly partials
partial <- pacf(
audusd %>%
mutate(minute = minute(timestamp)) %>%
filter(minute == 0) %>%
select(close) %>%
pull(),
lags = 20, plot = FALSE)
plot(partial[2:20], main = 'Hourly PACF')
 Finally, at the daily resolution:
Finally, at the daily resolution:
# daily partials
partial <- pacf(
audusd %>%
mutate(hour = hour(timestamp)) %>%
filter(hour == 0) %>%
select(close) %>%
pull(),
lags = 20, plot = FALSE)
plot(partial[2:20], main = 'Daily PACF')
 There’s a pattern emerging there, with fewer and fewer significant partial correlations as we increase the resolution.
We can try an \(AR(10)\) model using ten-minutely data. Follow the same procedure above, where we calculate the coefficients in R, then hard-code them in our Zorro script. This gives the following result:
There’s a pattern emerging there, with fewer and fewer significant partial correlations as we increase the resolution.
We can try an \(AR(10)\) model using ten-minutely data. Follow the same procedure above, where we calculate the coefficients in R, then hard-code them in our Zorro script. This gives the following result:
 We managed to triple our average cost per trade, but it’s still not going to come close to covering costs.
At this point, it’s becoming quite clear (if it wasn’t already) that this is a very marginal trade, no matter how you cut it. However, some other things that might be worth considering include:
We managed to triple our average cost per trade, but it’s still not going to come close to covering costs.
At this point, it’s becoming quite clear (if it wasn’t already) that this is a very marginal trade, no matter how you cut it. However, some other things that might be worth considering include:
- If we assumed that our predictions were both useful in terms of magnitude as well as direction, we could implement a prediction threshold such that we would trade only when the prediction is a certain distance from the current price.
- It would be reasonable to think that when volatility is higher, price tends to move further. To the extent that an edge exists, it will be larger as a percent of costs the larger the volatility. Since volatility is somewhat predictable (at least in a noisy sense), we might be able to improve the average profit per trade by simply not trading when we think volatility is going to be low.
- Finally, we may want to try re-fitting the model at regular intervals. To check if that’s a useful thing to do, you could look for evidence of persistence of model coefficients. That is, are the model coefficients estimated over one window similar to those fitted over the next window? You can backtest this approach using the Zorro and R scripts above – simply don’t pass the
fixedparameter from Zorro and think about how much data you want in your fitting window.
Conclusion
Fitting an autoregressive model to historical prices of FX was a fun exercise that yielded a surprising result: namely, the deviation of the price series from the assumption of a random walk. The analysis suggests that short-term mean reversion of FX exists, but is unlikely to be something we can trade effectively. When we think about what the strategy is really doing, it’s merely trading mean-reversion around a recent price level. It’s unlikely that the ten AR lags are doing anything more nuanced than trading a noisy short-term reversal effect that could probably be harnessed in a more simple and effective way. For example, we could very likely get a similar result with less fuss by looking to fade extreme moves in the short term. Maybe there are sophisticated and important interdependencies between those ten lags, but I don’t think we should assume that there are. In any event, no matter how we trade this effect, it’s unlikely to yield profit after costs.Free Case Study:
A wantaway engineer’s journey into professional trading and out again
I went from engineering to an equity partnership at a prop trading firm to running my own systematic trading operation from home in Western Australia.
This case study is the full story – every mistake, every breakthrough, and some things I trade today.


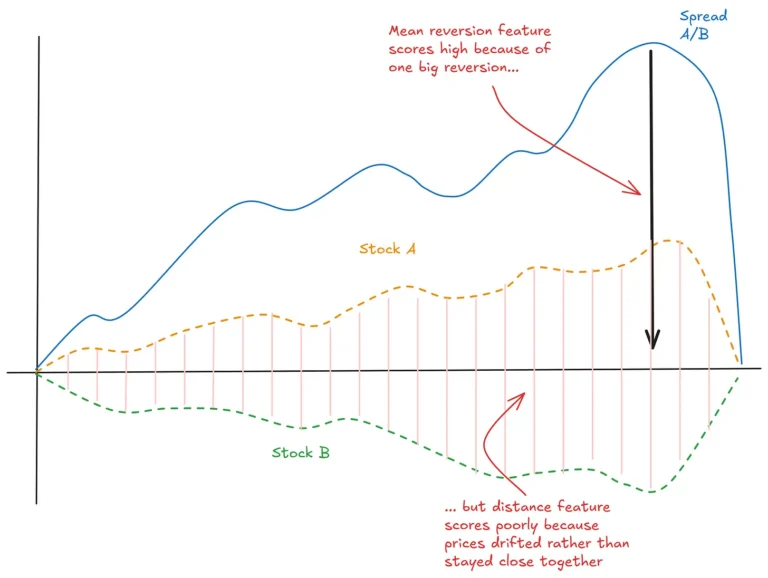
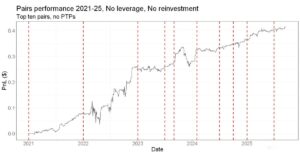
More of these posts please! I have been trying to get more experience using R applied to finance and this sort of post is very informative!