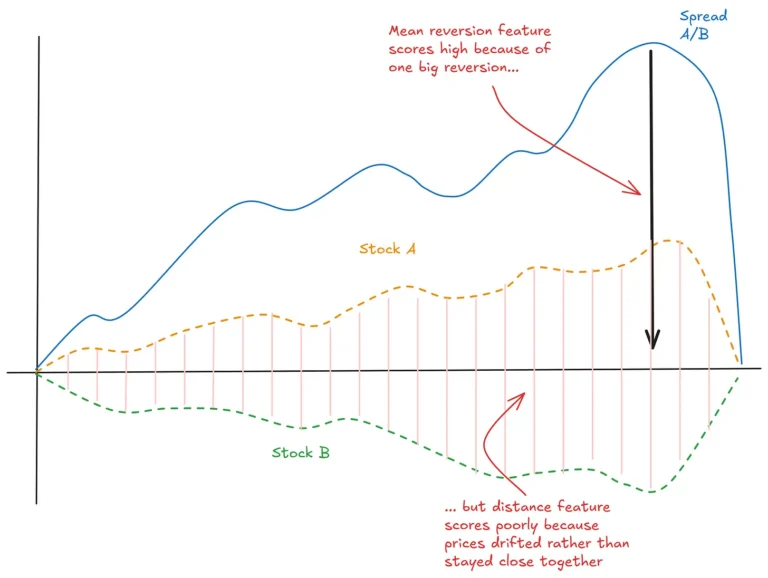
Holding data in a tidy format works wonders for one’s productivity.
Here we will explore the
tidyr package, which is all about creating tidy data.
In particular, let’s develop an understanding of the
tidyr::pivot_longer and
tidyr::pivot_wider functions for switching between different formats of tidy data.
In this video, you’ll learn:
- What tidy data looks like
- Why it’s a sensible approach
- The difference between long and wide tidy data
- How to efficiently switch between the two format
- When and why you’d use each of the two formats
What’s tidy data?
Tidy data is data where:
- Every column is variable.
- Every row is an observation.
- Every cell is a single value.
Why do we care?
It turns out there are huge benefits to thinking about the “shape” of your data and the best way to structure and manipulate it for your problem.
Tidy data is a standard way of shaping data that facilitates analysis. In particular, tidy data works very well with the tidyverse tools. Which means less time spent transforming and cleaning data and more time spent solving problems. In short, structuring data to facilitate analysis is an enormous productivity hack.
Thinking in these terms has had a MASSIVE impact on the effectiveness and speed of our research. We’re going to cover this in some detail in the Armageddon bootcamp, along with some specific patterns for doing trading analysis.
Wide vs Long Data
Let’s take a look at some long-format data. This code loads a long dataframe of daily returns for various indexes and prints the observations from the beginning of March 2020:
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyverse, here, knitr, kableExtra)
load(here('data', 'indexreturns.RData'))
dailyindex_df <- dailyindex_df %>%
filter(date >= '2020-03-01')
dailyindex_df %>%
kable() %>%
kable_styling(full_width = FALSE, position = 'center') %>%
scroll_box(width = '800px', height = '300px')
| date |
ticker |
returns |
| 2020-03-02 |
EQ_US |
0.0460048 |
| 2020-03-02 |
EQ_NONUS_DEV |
0.0111621 |
| 2020-03-02 |
EQ_EMER |
0.0114468 |
| 2020-03-02 |
TN_US |
-0.0008475 |
| 2020-03-02 |
TB_US |
-0.0073579 |
| 2020-03-02 |
BOND_EMER |
0.0051502 |
| 2020-03-02 |
GOLD |
0.0179376 |
| 2020-03-03 |
EQ_US |
-0.0280740 |
| 2020-03-03 |
EQ_NONUS_DEV |
0.0097820 |
| 2020-03-03 |
EQ_EMER |
0.0106093 |
| 2020-03-03 |
TN_US |
0.0093299 |
| 2020-03-03 |
TB_US |
0.0154987 |
| 2020-03-03 |
BOND_EMER |
0.0093937 |
| 2020-03-03 |
GOLD |
0.0311450 |
| 2020-03-04 |
EQ_US |
0.0422302 |
| 2020-03-04 |
EQ_NONUS_DEV |
0.0062777 |
| 2020-03-04 |
EQ_EMER |
0.0097196 |
| 2020-03-04 |
TN_US |
-0.0016807 |
| 2020-03-04 |
TB_US |
-0.0099536 |
| 2020-03-04 |
BOND_EMER |
0.0059222 |
| 2020-03-04 |
GOLD |
-0.0008743 |
| 2020-03-05 |
EQ_US |
-0.0336854 |
| 2020-03-05 |
EQ_NONUS_DEV |
-0.0014521 |
| 2020-03-05 |
EQ_EMER |
0.0014743 |
| 2020-03-05 |
TN_US |
0.0050505 |
| 2020-03-05 |
TB_US |
0.0227882 |
| 2020-03-05 |
BOND_EMER |
-0.0067283 |
| 2020-03-05 |
GOLD |
0.0151949 |
| 2020-03-06 |
EQ_US |
-0.0170369 |
| 2020-03-06 |
EQ_NONUS_DEV |
-0.0232132 |
| 2020-03-06 |
EQ_EMER |
-0.0262282 |
| 2020-03-06 |
TN_US |
0.0041876 |
| 2020-03-06 |
TB_US |
0.0498034 |
| 2020-03-06 |
BOND_EMER |
-0.0076207 |
| 2020-03-06 |
GOLD |
0.0026644 |
| 2020-03-09 |
EQ_US |
-0.0761665 |
| 2020-03-09 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-09 |
EQ_EMER |
0.0000000 |
| 2020-03-09 |
TN_US |
0.0041701 |
| 2020-03-09 |
TB_US |
0.0262172 |
| 2020-03-09 |
BOND_EMER |
0.0000000 |
| 2020-03-09 |
GOLD |
0.0018757 |
| 2020-03-10 |
EQ_US |
0.0494037 |
| 2020-03-10 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-10 |
EQ_EMER |
0.0000000 |
| 2020-03-10 |
TN_US |
-0.0091362 |
| 2020-03-10 |
TB_US |
-0.0486618 |
| 2020-03-10 |
BOND_EMER |
-0.0477816 |
| 2020-03-10 |
GOLD |
-0.0091271 |
| 2020-03-11 |
EQ_US |
-0.0487713 |
| 2020-03-11 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-11 |
EQ_EMER |
0.0000000 |
| 2020-03-11 |
TN_US |
-0.0025147 |
| 2020-03-11 |
TB_US |
-0.0108696 |
| 2020-03-11 |
BOND_EMER |
-0.0206093 |
| 2020-03-11 |
GOLD |
-0.0107857 |
| 2020-03-12 |
EQ_US |
-0.0949084 |
| 2020-03-12 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-12 |
EQ_EMER |
0.0000000 |
| 2020-03-12 |
TN_US |
0.0008403 |
| 2020-03-12 |
TB_US |
-0.0155139 |
| 2020-03-12 |
BOND_EMER |
0.0000000 |
| 2020-03-12 |
GOLD |
-0.0317549 |
| 2020-03-13 |
EQ_US |
0.0931900 |
| 2020-03-13 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-13 |
EQ_EMER |
0.0000000 |
| 2020-03-13 |
TN_US |
-0.0058774 |
| 2020-03-13 |
TB_US |
-0.0216678 |
| 2020-03-13 |
BOND_EMER |
-0.0439158 |
| 2020-03-13 |
GOLD |
-0.0462765 |
| 2020-03-16 |
EQ_US |
-0.1197921 |
| 2020-03-16 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-16 |
EQ_EMER |
0.0000000 |
| 2020-03-16 |
TN_US |
0.0126689 |
| 2020-03-16 |
TB_US |
0.0510067 |
| 2020-03-16 |
BOND_EMER |
-0.0325359 |
| 2020-03-16 |
GOLD |
-0.0203396 |
| 2020-03-17 |
EQ_US |
0.0597801 |
| 2020-03-17 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-17 |
EQ_EMER |
0.0000000 |
| 2020-03-17 |
TN_US |
-0.0133445 |
| 2020-03-17 |
TB_US |
-0.0587484 |
| 2020-03-17 |
BOND_EMER |
-0.0197824 |
| 2020-03-17 |
GOLD |
0.0265681 |
| 2020-03-18 |
EQ_US |
-0.0517360 |
| 2020-03-18 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-18 |
EQ_EMER |
0.0000000 |
| 2020-03-18 |
TN_US |
-0.0067625 |
| 2020-03-18 |
TB_US |
-0.0434193 |
| 2020-03-18 |
BOND_EMER |
-0.0544904 |
| 2020-03-18 |
GOLD |
-0.0311081 |
| 2020-03-19 |
EQ_US |
0.0047010 |
| 2020-03-19 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-19 |
EQ_EMER |
0.0000000 |
| 2020-03-19 |
TN_US |
0.0017021 |
| 2020-03-19 |
TB_US |
0.0007092 |
| 2020-03-19 |
BOND_EMER |
-0.0234792 |
| 2020-03-19 |
GOLD |
0.0011498 |
| 2020-03-20 |
EQ_US |
-0.0431907 |
| 2020-03-20 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-20 |
EQ_EMER |
0.0000000 |
| 2020-03-20 |
TN_US |
0.0144435 |
| 2020-03-20 |
TB_US |
0.0652020 |
| 2020-03-20 |
BOND_EMER |
0.0142077 |
| 2020-03-20 |
GOLD |
0.0039756 |
| 2020-03-23 |
EQ_US |
-0.0292942 |
| 2020-03-23 |
EQ_NONUS_DEV |
-0.2532532 |
| 2020-03-23 |
EQ_EMER |
0.0000000 |
| 2020-03-23 |
TN_US |
0.0083752 |
| 2020-03-23 |
TB_US |
0.0419162 |
| 2020-03-23 |
BOND_EMER |
-0.0215517 |
| 2020-03-23 |
GOLD |
0.0568462 |
| 2020-03-24 |
EQ_US |
0.0939740 |
| 2020-03-24 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-24 |
EQ_EMER |
0.0000000 |
| 2020-03-24 |
TN_US |
-0.0041528 |
| 2020-03-24 |
TB_US |
-0.0051086 |
| 2020-03-24 |
BOND_EMER |
0.0121145 |
| 2020-03-24 |
GOLD |
0.0575354 |
| 2020-03-25 |
EQ_US |
0.0115569 |
| 2020-03-25 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-25 |
EQ_EMER |
0.0000000 |
| 2020-03-25 |
TN_US |
0.0008340 |
| 2020-03-25 |
TB_US |
-0.0064185 |
| 2020-03-25 |
BOND_EMER |
0.0315560 |
| 2020-03-25 |
GOLD |
-0.0174002 |
| 2020-03-26 |
EQ_US |
0.0624207 |
| 2020-03-26 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-26 |
EQ_EMER |
0.0000000 |
| 2020-03-26 |
TN_US |
0.0016667 |
| 2020-03-26 |
TB_US |
0.0064599 |
| 2020-03-26 |
BOND_EMER |
0.0295359 |
| 2020-03-26 |
GOLD |
0.0159455 |
| 2020-03-27 |
EQ_US |
-0.0336616 |
| 2020-03-27 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-27 |
EQ_EMER |
0.0000000 |
| 2020-03-27 |
TN_US |
0.0049917 |
| 2020-03-27 |
TB_US |
0.0237484 |
| 2020-03-27 |
BOND_EMER |
-0.0081967 |
| 2020-03-27 |
GOLD |
-0.0037858 |
| 2020-03-30 |
EQ_US |
0.0336403 |
| 2020-03-30 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-30 |
EQ_EMER |
0.0000000 |
| 2020-03-30 |
TN_US |
-0.0008278 |
| 2020-03-30 |
TB_US |
-0.0050157 |
| 2020-03-30 |
BOND_EMER |
-0.0144628 |
| 2020-03-30 |
GOLD |
-0.0065711 |
| 2020-03-31 |
EQ_US |
-0.0159221 |
| 2020-03-31 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-31 |
EQ_EMER |
0.0000000 |
| 2020-03-31 |
TN_US |
-0.0016570 |
| 2020-03-31 |
TB_US |
-0.0144928 |
| 2020-03-31 |
BOND_EMER |
0.0115304 |
| 2020-03-31 |
GOLD |
-0.0283711 |
| 2020-04-01 |
EQ_US |
-0.0441380 |
| 2020-04-01 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-04-01 |
EQ_EMER |
0.0000000 |
| 2020-04-01 |
TN_US |
0.0008299 |
| 2020-04-01 |
TB_US |
0.0147059 |
| 2020-04-01 |
BOND_EMER |
-0.0124352 |
| 2020-04-01 |
GOLD |
-0.0032808 |
| 2020-04-02 |
EQ_US |
0.0230223 |
| 2020-04-02 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-04-02 |
EQ_EMER |
0.0000000 |
| 2020-04-02 |
TN_US |
0.0008292 |
| 2020-04-02 |
TB_US |
0.0056711 |
| 2020-04-02 |
BOND_EMER |
0.0000000 |
| 2020-04-02 |
GOLD |
0.0291310 |
Long data is presented with one or more columns containing a key and another containing all the values.
In this example, the key, or so-called “unit of analysis: is date-ticker. That is, each value (in the returns column) is uniquely associated with a date-ticker joint key.
The joint key date-ticker would be the starting point of any analysis we’d want to do on this data set.
This is often easier to manage and process. However, if you’re used to looking at spreadsheets, it can be harder to understand intuitively.
(I think that this difficulty evaporates fairly quickly once you start using the tools).
While structuring data as key-value pairs might seem odd if you’re not used to it, it does actually facilitate your conceptual clarity of the problem at hand.
For example, in the example above, it is clear that the unique identifier of each return is the date-ticker joint key.
With that clarity, it becomes much simpler to imagine the steps in an analysis workflow. You get quite productive and effective at this with a little practice.
Let’s compare this with the same data in wide format:
dailyindex_df %>%
pivot_wider(names_from = ticker, values_from = returns) %>%
kable() %>%
kable_styling(position = 'center') %>%
scroll_box(width = '800px', height = '300px')
| date |
EQ_US |
EQ_NONUS_DEV |
EQ_EMER |
TN_US |
TB_US |
BOND_EMER |
GOLD |
| 2020-03-02 |
0.0460048 |
0.0111621 |
0.0114468 |
-0.0008475 |
-0.0073579 |
0.0051502 |
0.0179376 |
| 2020-03-03 |
-0.0280740 |
0.0097820 |
0.0106093 |
0.0093299 |
0.0154987 |
0.0093937 |
0.0311450 |
| 2020-03-04 |
0.0422302 |
0.0062777 |
0.0097196 |
-0.0016807 |
-0.0099536 |
0.0059222 |
-0.0008743 |
| 2020-03-05 |
-0.0336854 |
-0.0014521 |
0.0014743 |
0.0050505 |
0.0227882 |
-0.0067283 |
0.0151949 |
| 2020-03-06 |
-0.0170369 |
-0.0232132 |
-0.0262282 |
0.0041876 |
0.0498034 |
-0.0076207 |
0.0026644 |
| 2020-03-09 |
-0.0761665 |
0.0000000 |
0.0000000 |
0.0041701 |
0.0262172 |
0.0000000 |
0.0018757 |
| 2020-03-10 |
0.0494037 |
0.0000000 |
0.0000000 |
-0.0091362 |
-0.0486618 |
-0.0477816 |
-0.0091271 |
| 2020-03-11 |
-0.0487713 |
0.0000000 |
0.0000000 |
-0.0025147 |
-0.0108696 |
-0.0206093 |
-0.0107857 |
| 2020-03-12 |
-0.0949084 |
0.0000000 |
0.0000000 |
0.0008403 |
-0.0155139 |
0.0000000 |
-0.0317549 |
| 2020-03-13 |
0.0931900 |
0.0000000 |
0.0000000 |
-0.0058774 |
-0.0216678 |
-0.0439158 |
-0.0462765 |
| 2020-03-16 |
-0.1197921 |
0.0000000 |
0.0000000 |
0.0126689 |
0.0510067 |
-0.0325359 |
-0.0203396 |
| 2020-03-17 |
0.0597801 |
0.0000000 |
0.0000000 |
-0.0133445 |
-0.0587484 |
-0.0197824 |
0.0265681 |
| 2020-03-18 |
-0.0517360 |
0.0000000 |
0.0000000 |
-0.0067625 |
-0.0434193 |
-0.0544904 |
-0.0311081 |
| 2020-03-19 |
0.0047010 |
0.0000000 |
0.0000000 |
0.0017021 |
0.0007092 |
-0.0234792 |
0.0011498 |
| 2020-03-20 |
-0.0431907 |
0.0000000 |
0.0000000 |
0.0144435 |
0.0652020 |
0.0142077 |
0.0039756 |
| 2020-03-23 |
-0.0292942 |
-0.2532532 |
0.0000000 |
0.0083752 |
0.0419162 |
-0.0215517 |
0.0568462 |
| 2020-03-24 |
0.0939740 |
0.0000000 |
0.0000000 |
-0.0041528 |
-0.0051086 |
0.0121145 |
0.0575354 |
| 2020-03-25 |
0.0115569 |
0.0000000 |
0.0000000 |
0.0008340 |
-0.0064185 |
0.0315560 |
-0.0174002 |
| 2020-03-26 |
0.0624207 |
0.0000000 |
0.0000000 |
0.0016667 |
0.0064599 |
0.0295359 |
0.0159455 |
| 2020-03-27 |
-0.0336616 |
0.0000000 |
0.0000000 |
0.0049917 |
0.0237484 |
-0.0081967 |
-0.0037858 |
| 2020-03-30 |
0.0336403 |
0.0000000 |
0.0000000 |
-0.0008278 |
-0.0050157 |
-0.0144628 |
-0.0065711 |
| 2020-03-31 |
-0.0159221 |
0.0000000 |
0.0000000 |
-0.0016570 |
-0.0144928 |
0.0115304 |
-0.0283711 |
| 2020-04-01 |
-0.0441380 |
0.0000000 |
0.0000000 |
0.0008299 |
0.0147059 |
-0.0124352 |
-0.0032808 |
| 2020-04-02 |
0.0230223 |
0.0000000 |
0.0000000 |
0.0008292 |
0.0056711 |
0.0000000 |
0.0291310 |
This might look more familiar. Here we have a row for each date and a column for the return corresponding to each index. The unique values in the ticker column are actual columns in this wide format.
Data in this format is probably more amenable human consumption.
So which is better – wide or long format?
It depends!
You’ll find that storing your data in long format facilitates exploration and analysis, particularly if you use the
tidyverse tools. We highly recommend that you do all your tidy analysis in long format unless you have a good reason not to.
Long format data is also easy to maintain – adding a new variable
(a new ticker, say) is as simple as appending rows to the bottom of the existing data frame (and maybe sorting it by date, if you wanted to).
One use case that you see all the time is using ggplot to visualise a variable for more than one member of some organising category, for example, a time series plot of a bunch of different price curves where the organising category is ticker.
On the other hand, wide-format data might be a better choice if you intend for a human to consume the data.
You will also find certain functions and algorithms that expect data in this format, for example
stats::cor.
The practical reality
A good rule of thumb (and one that we follow) is to keep your data in long format whenever you’re doing any data manipulation or processing and save wide format for displaying it.
Of course, there are exceptions and sometimes you have a reason not to do your processing in long format, for instance when a function requires a wide data frame.
That means that in reality, you’ll often find yourself wanting to switch between long and wide format. Fortunately, Fortunately, using the
tidyr package, it is very simple to convert from long to wide format and back again.
Pivoting from long to wide
We’ve already seen an example of pivoting from long to wide format. Let’s explore that in a little more detail.
We use
tidyr::pivot_wider to go from long to wide.
The most important arguments to the function are
id_cols,
names_from and
values_from, and they each specify a column in our long dataframe.
- The
id_cols column specifies the unique identifier of each observation in our wide data frame.
- The unique values in the
names_from column become the column names in the wide data frame.
- The values in the
values_from column gets populated into the cells of the wide data frame.
In our example:
- We want to index our wide dataframe by date, so we specify
id_cols = date
- We want the tickers to form columns in the wide dataframe, so we specify
names_from = ticker
- We want to populate our wide dataframe with returns values, so we specify
values_from = returns
Here’s what that looks like:
dailyindex_df %>%
pivot_wider(id_cols = date, names_from = ticker, values_from = returns) %>%
kable() %>%
kable_styling(position = 'center') %>%
scroll_box(width = '800px', height = '300px')
| date |
EQ_US |
EQ_NONUS_DEV |
EQ_EMER |
TN_US |
TB_US |
BOND_EMER |
GOLD |
| 2020-03-02 |
0.0460048 |
0.0111621 |
0.0114468 |
-0.0008475 |
-0.0073579 |
0.0051502 |
0.0179376 |
| 2020-03-03 |
-0.0280740 |
0.0097820 |
0.0106093 |
0.0093299 |
0.0154987 |
0.0093937 |
0.0311450 |
| 2020-03-04 |
0.0422302 |
0.0062777 |
0.0097196 |
-0.0016807 |
-0.0099536 |
0.0059222 |
-0.0008743 |
| 2020-03-05 |
-0.0336854 |
-0.0014521 |
0.0014743 |
0.0050505 |
0.0227882 |
-0.0067283 |
0.0151949 |
| 2020-03-06 |
-0.0170369 |
-0.0232132 |
-0.0262282 |
0.0041876 |
0.0498034 |
-0.0076207 |
0.0026644 |
| 2020-03-09 |
-0.0761665 |
0.0000000 |
0.0000000 |
0.0041701 |
0.0262172 |
0.0000000 |
0.0018757 |
| 2020-03-10 |
0.0494037 |
0.0000000 |
0.0000000 |
-0.0091362 |
-0.0486618 |
-0.0477816 |
-0.0091271 |
| 2020-03-11 |
-0.0487713 |
0.0000000 |
0.0000000 |
-0.0025147 |
-0.0108696 |
-0.0206093 |
-0.0107857 |
| 2020-03-12 |
-0.0949084 |
0.0000000 |
0.0000000 |
0.0008403 |
-0.0155139 |
0.0000000 |
-0.0317549 |
| 2020-03-13 |
0.0931900 |
0.0000000 |
0.0000000 |
-0.0058774 |
-0.0216678 |
-0.0439158 |
-0.0462765 |
| 2020-03-16 |
-0.1197921 |
0.0000000 |
0.0000000 |
0.0126689 |
0.0510067 |
-0.0325359 |
-0.0203396 |
| 2020-03-17 |
0.0597801 |
0.0000000 |
0.0000000 |
-0.0133445 |
-0.0587484 |
-0.0197824 |
0.0265681 |
| 2020-03-18 |
-0.0517360 |
0.0000000 |
0.0000000 |
-0.0067625 |
-0.0434193 |
-0.0544904 |
-0.0311081 |
| 2020-03-19 |
0.0047010 |
0.0000000 |
0.0000000 |
0.0017021 |
0.0007092 |
-0.0234792 |
0.0011498 |
| 2020-03-20 |
-0.0431907 |
0.0000000 |
0.0000000 |
0.0144435 |
0.0652020 |
0.0142077 |
0.0039756 |
| 2020-03-23 |
-0.0292942 |
-0.2532532 |
0.0000000 |
0.0083752 |
0.0419162 |
-0.0215517 |
0.0568462 |
| 2020-03-24 |
0.0939740 |
0.0000000 |
0.0000000 |
-0.0041528 |
-0.0051086 |
0.0121145 |
0.0575354 |
| 2020-03-25 |
0.0115569 |
0.0000000 |
0.0000000 |
0.0008340 |
-0.0064185 |
0.0315560 |
-0.0174002 |
| 2020-03-26 |
0.0624207 |
0.0000000 |
0.0000000 |
0.0016667 |
0.0064599 |
0.0295359 |
0.0159455 |
| 2020-03-27 |
-0.0336616 |
0.0000000 |
0.0000000 |
0.0049917 |
0.0237484 |
-0.0081967 |
-0.0037858 |
| 2020-03-30 |
0.0336403 |
0.0000000 |
0.0000000 |
-0.0008278 |
-0.0050157 |
-0.0144628 |
-0.0065711 |
| 2020-03-31 |
-0.0159221 |
0.0000000 |
0.0000000 |
-0.0016570 |
-0.0144928 |
0.0115304 |
-0.0283711 |
| 2020-04-01 |
-0.0441380 |
0.0000000 |
0.0000000 |
0.0008299 |
0.0147059 |
-0.0124352 |
-0.0032808 |
| 2020-04-02 |
0.0230223 |
0.0000000 |
0.0000000 |
0.0008292 |
0.0056711 |
0.0000000 |
0.0291310 |
Could that be any easier?
Actually, yes!
id_cols defaults to any column or columns that aren’t specified by the
names_from and
values_from arguments. So in our case, we could actually not even bother with the
id_cols argument:
dailyindex_df_wide <- dailyindex_df %>%
pivot_wider(names_from = ticker, values_from = returns)
dailyindex_df_wide %>%
kable() %>%
kable_styling(position = 'center') %>%
scroll_box(width = '800px', height = '300px')
| date |
EQ_US |
EQ_NONUS_DEV |
EQ_EMER |
TN_US |
TB_US |
BOND_EMER |
GOLD |
| 2020-03-02 |
0.0460048 |
0.0111621 |
0.0114468 |
-0.0008475 |
-0.0073579 |
0.0051502 |
0.0179376 |
| 2020-03-03 |
-0.0280740 |
0.0097820 |
0.0106093 |
0.0093299 |
0.0154987 |
0.0093937 |
0.0311450 |
| 2020-03-04 |
0.0422302 |
0.0062777 |
0.0097196 |
-0.0016807 |
-0.0099536 |
0.0059222 |
-0.0008743 |
| 2020-03-05 |
-0.0336854 |
-0.0014521 |
0.0014743 |
0.0050505 |
0.0227882 |
-0.0067283 |
0.0151949 |
| 2020-03-06 |
-0.0170369 |
-0.0232132 |
-0.0262282 |
0.0041876 |
0.0498034 |
-0.0076207 |
0.0026644 |
| 2020-03-09 |
-0.0761665 |
0.0000000 |
0.0000000 |
0.0041701 |
0.0262172 |
0.0000000 |
0.0018757 |
| 2020-03-10 |
0.0494037 |
0.0000000 |
0.0000000 |
-0.0091362 |
-0.0486618 |
-0.0477816 |
-0.0091271 |
| 2020-03-11 |
-0.0487713 |
0.0000000 |
0.0000000 |
-0.0025147 |
-0.0108696 |
-0.0206093 |
-0.0107857 |
| 2020-03-12 |
-0.0949084 |
0.0000000 |
0.0000000 |
0.0008403 |
-0.0155139 |
0.0000000 |
-0.0317549 |
| 2020-03-13 |
0.0931900 |
0.0000000 |
0.0000000 |
-0.0058774 |
-0.0216678 |
-0.0439158 |
-0.0462765 |
| 2020-03-16 |
-0.1197921 |
0.0000000 |
0.0000000 |
0.0126689 |
0.0510067 |
-0.0325359 |
-0.0203396 |
| 2020-03-17 |
0.0597801 |
0.0000000 |
0.0000000 |
-0.0133445 |
-0.0587484 |
-0.0197824 |
0.0265681 |
| 2020-03-18 |
-0.0517360 |
0.0000000 |
0.0000000 |
-0.0067625 |
-0.0434193 |
-0.0544904 |
-0.0311081 |
| 2020-03-19 |
0.0047010 |
0.0000000 |
0.0000000 |
0.0017021 |
0.0007092 |
-0.0234792 |
0.0011498 |
| 2020-03-20 |
-0.0431907 |
0.0000000 |
0.0000000 |
0.0144435 |
0.0652020 |
0.0142077 |
0.0039756 |
| 2020-03-23 |
-0.0292942 |
-0.2532532 |
0.0000000 |
0.0083752 |
0.0419162 |
-0.0215517 |
0.0568462 |
| 2020-03-24 |
0.0939740 |
0.0000000 |
0.0000000 |
-0.0041528 |
-0.0051086 |
0.0121145 |
0.0575354 |
| 2020-03-25 |
0.0115569 |
0.0000000 |
0.0000000 |
0.0008340 |
-0.0064185 |
0.0315560 |
-0.0174002 |
| 2020-03-26 |
0.0624207 |
0.0000000 |
0.0000000 |
0.0016667 |
0.0064599 |
0.0295359 |
0.0159455 |
| 2020-03-27 |
-0.0336616 |
0.0000000 |
0.0000000 |
0.0049917 |
0.0237484 |
-0.0081967 |
-0.0037858 |
| 2020-03-30 |
0.0336403 |
0.0000000 |
0.0000000 |
-0.0008278 |
-0.0050157 |
-0.0144628 |
-0.0065711 |
| 2020-03-31 |
-0.0159221 |
0.0000000 |
0.0000000 |
-0.0016570 |
-0.0144928 |
0.0115304 |
-0.0283711 |
| 2020-04-01 |
-0.0441380 |
0.0000000 |
0.0000000 |
0.0008299 |
0.0147059 |
-0.0124352 |
-0.0032808 |
| 2020-04-02 |
0.0230223 |
0.0000000 |
0.0000000 |
0.0008292 |
0.0056711 |
0.0000000 |
0.0291310 |
Same result as above. Brilliant.
Pivoting from wide to long
For pivoting from wide to long, we use
tidry::pivot_longer.
The most important arguments to the function are
cols,
names_to and
values_to. You can probably guess at their relationship to the arguments to
pivot_wider.
cols specifies the columns that we want to take from wide to long.names_to specifies a name for the column in our long data frame that will hold the column names from the wide data frame.values_to specifies a name for the column in our long data frame that will hold the values in the cells of the wide data frame.
In our example:
- We want to take the columns holding the returns for each ticker from wide to long, so we want
cols to take all the columns except date. We can do that by specifying cols = -date
- We want the names of the
cols to be held in a long variable called tickers, so we specify names_to = "ticker". Note that "ticker" here is a string variable.
- We want to hold the values from our wide columns in a long column called
"returns" so we specify values_to = "returns". Again note the string variable.
Here’s what that looks like:
dailyindex_df_wide %>%
pivot_longer(cols = -date, names_to = 'ticker', values_to= 'returns') %>%
kable() %>%
kable_styling(full_width = FALSE, position = 'center') %>%
scroll_box(width = '800px', height = '300px')
| date |
ticker |
returns |
| 2020-03-02 |
EQ_US |
0.0460048 |
| 2020-03-02 |
EQ_NONUS_DEV |
0.0111621 |
| 2020-03-02 |
EQ_EMER |
0.0114468 |
| 2020-03-02 |
TN_US |
-0.0008475 |
| 2020-03-02 |
TB_US |
-0.0073579 |
| 2020-03-02 |
BOND_EMER |
0.0051502 |
| 2020-03-02 |
GOLD |
0.0179376 |
| 2020-03-03 |
EQ_US |
-0.0280740 |
| 2020-03-03 |
EQ_NONUS_DEV |
0.0097820 |
| 2020-03-03 |
EQ_EMER |
0.0106093 |
| 2020-03-03 |
TN_US |
0.0093299 |
| 2020-03-03 |
TB_US |
0.0154987 |
| 2020-03-03 |
BOND_EMER |
0.0093937 |
| 2020-03-03 |
GOLD |
0.0311450 |
| 2020-03-04 |
EQ_US |
0.0422302 |
| 2020-03-04 |
EQ_NONUS_DEV |
0.0062777 |
| 2020-03-04 |
EQ_EMER |
0.0097196 |
| 2020-03-04 |
TN_US |
-0.0016807 |
| 2020-03-04 |
TB_US |
-0.0099536 |
| 2020-03-04 |
BOND_EMER |
0.0059222 |
| 2020-03-04 |
GOLD |
-0.0008743 |
| 2020-03-05 |
EQ_US |
-0.0336854 |
| 2020-03-05 |
EQ_NONUS_DEV |
-0.0014521 |
| 2020-03-05 |
EQ_EMER |
0.0014743 |
| 2020-03-05 |
TN_US |
0.0050505 |
| 2020-03-05 |
TB_US |
0.0227882 |
| 2020-03-05 |
BOND_EMER |
-0.0067283 |
| 2020-03-05 |
GOLD |
0.0151949 |
| 2020-03-06 |
EQ_US |
-0.0170369 |
| 2020-03-06 |
EQ_NONUS_DEV |
-0.0232132 |
| 2020-03-06 |
EQ_EMER |
-0.0262282 |
| 2020-03-06 |
TN_US |
0.0041876 |
| 2020-03-06 |
TB_US |
0.0498034 |
| 2020-03-06 |
BOND_EMER |
-0.0076207 |
| 2020-03-06 |
GOLD |
0.0026644 |
| 2020-03-09 |
EQ_US |
-0.0761665 |
| 2020-03-09 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-09 |
EQ_EMER |
0.0000000 |
| 2020-03-09 |
TN_US |
0.0041701 |
| 2020-03-09 |
TB_US |
0.0262172 |
| 2020-03-09 |
BOND_EMER |
0.0000000 |
| 2020-03-09 |
GOLD |
0.0018757 |
| 2020-03-10 |
EQ_US |
0.0494037 |
| 2020-03-10 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-10 |
EQ_EMER |
0.0000000 |
| 2020-03-10 |
TN_US |
-0.0091362 |
| 2020-03-10 |
TB_US |
-0.0486618 |
| 2020-03-10 |
BOND_EMER |
-0.0477816 |
| 2020-03-10 |
GOLD |
-0.0091271 |
| 2020-03-11 |
EQ_US |
-0.0487713 |
| 2020-03-11 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-11 |
EQ_EMER |
0.0000000 |
| 2020-03-11 |
TN_US |
-0.0025147 |
| 2020-03-11 |
TB_US |
-0.0108696 |
| 2020-03-11 |
BOND_EMER |
-0.0206093 |
| 2020-03-11 |
GOLD |
-0.0107857 |
| 2020-03-12 |
EQ_US |
-0.0949084 |
| 2020-03-12 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-12 |
EQ_EMER |
0.0000000 |
| 2020-03-12 |
TN_US |
0.0008403 |
| 2020-03-12 |
TB_US |
-0.0155139 |
| 2020-03-12 |
BOND_EMER |
0.0000000 |
| 2020-03-12 |
GOLD |
-0.0317549 |
| 2020-03-13 |
EQ_US |
0.0931900 |
| 2020-03-13 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-13 |
EQ_EMER |
0.0000000 |
| 2020-03-13 |
TN_US |
-0.0058774 |
| 2020-03-13 |
TB_US |
-0.0216678 |
| 2020-03-13 |
BOND_EMER |
-0.0439158 |
| 2020-03-13 |
GOLD |
-0.0462765 |
| 2020-03-16 |
EQ_US |
-0.1197921 |
| 2020-03-16 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-16 |
EQ_EMER |
0.0000000 |
| 2020-03-16 |
TN_US |
0.0126689 |
| 2020-03-16 |
TB_US |
0.0510067 |
| 2020-03-16 |
BOND_EMER |
-0.0325359 |
| 2020-03-16 |
GOLD |
-0.0203396 |
| 2020-03-17 |
EQ_US |
0.0597801 |
| 2020-03-17 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-17 |
EQ_EMER |
0.0000000 |
| 2020-03-17 |
TN_US |
-0.0133445 |
| 2020-03-17 |
TB_US |
-0.0587484 |
| 2020-03-17 |
BOND_EMER |
-0.0197824 |
| 2020-03-17 |
GOLD |
0.0265681 |
| 2020-03-18 |
EQ_US |
-0.0517360 |
| 2020-03-18 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-18 |
EQ_EMER |
0.0000000 |
| 2020-03-18 |
TN_US |
-0.0067625 |
| 2020-03-18 |
TB_US |
-0.0434193 |
| 2020-03-18 |
BOND_EMER |
-0.0544904 |
| 2020-03-18 |
GOLD |
-0.0311081 |
| 2020-03-19 |
EQ_US |
0.0047010 |
| 2020-03-19 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-19 |
EQ_EMER |
0.0000000 |
| 2020-03-19 |
TN_US |
0.0017021 |
| 2020-03-19 |
TB_US |
0.0007092 |
| 2020-03-19 |
BOND_EMER |
-0.0234792 |
| 2020-03-19 |
GOLD |
0.0011498 |
| 2020-03-20 |
EQ_US |
-0.0431907 |
| 2020-03-20 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-20 |
EQ_EMER |
0.0000000 |
| 2020-03-20 |
TN_US |
0.0144435 |
| 2020-03-20 |
TB_US |
0.0652020 |
| 2020-03-20 |
BOND_EMER |
0.0142077 |
| 2020-03-20 |
GOLD |
0.0039756 |
| 2020-03-23 |
EQ_US |
-0.0292942 |
| 2020-03-23 |
EQ_NONUS_DEV |
-0.2532532 |
| 2020-03-23 |
EQ_EMER |
0.0000000 |
| 2020-03-23 |
TN_US |
0.0083752 |
| 2020-03-23 |
TB_US |
0.0419162 |
| 2020-03-23 |
BOND_EMER |
-0.0215517 |
| 2020-03-23 |
GOLD |
0.0568462 |
| 2020-03-24 |
EQ_US |
0.0939740 |
| 2020-03-24 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-24 |
EQ_EMER |
0.0000000 |
| 2020-03-24 |
TN_US |
-0.0041528 |
| 2020-03-24 |
TB_US |
-0.0051086 |
| 2020-03-24 |
BOND_EMER |
0.0121145 |
| 2020-03-24 |
GOLD |
0.0575354 |
| 2020-03-25 |
EQ_US |
0.0115569 |
| 2020-03-25 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-25 |
EQ_EMER |
0.0000000 |
| 2020-03-25 |
TN_US |
0.0008340 |
| 2020-03-25 |
TB_US |
-0.0064185 |
| 2020-03-25 |
BOND_EMER |
0.0315560 |
| 2020-03-25 |
GOLD |
-0.0174002 |
| 2020-03-26 |
EQ_US |
0.0624207 |
| 2020-03-26 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-26 |
EQ_EMER |
0.0000000 |
| 2020-03-26 |
TN_US |
0.0016667 |
| 2020-03-26 |
TB_US |
0.0064599 |
| 2020-03-26 |
BOND_EMER |
0.0295359 |
| 2020-03-26 |
GOLD |
0.0159455 |
| 2020-03-27 |
EQ_US |
-0.0336616 |
| 2020-03-27 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-27 |
EQ_EMER |
0.0000000 |
| 2020-03-27 |
TN_US |
0.0049917 |
| 2020-03-27 |
TB_US |
0.0237484 |
| 2020-03-27 |
BOND_EMER |
-0.0081967 |
| 2020-03-27 |
GOLD |
-0.0037858 |
| 2020-03-30 |
EQ_US |
0.0336403 |
| 2020-03-30 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-30 |
EQ_EMER |
0.0000000 |
| 2020-03-30 |
TN_US |
-0.0008278 |
| 2020-03-30 |
TB_US |
-0.0050157 |
| 2020-03-30 |
BOND_EMER |
-0.0144628 |
| 2020-03-30 |
GOLD |
-0.0065711 |
| 2020-03-31 |
EQ_US |
-0.0159221 |
| 2020-03-31 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-03-31 |
EQ_EMER |
0.0000000 |
| 2020-03-31 |
TN_US |
-0.0016570 |
| 2020-03-31 |
TB_US |
-0.0144928 |
| 2020-03-31 |
BOND_EMER |
0.0115304 |
| 2020-03-31 |
GOLD |
-0.0283711 |
| 2020-04-01 |
EQ_US |
-0.0441380 |
| 2020-04-01 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-04-01 |
EQ_EMER |
0.0000000 |
| 2020-04-01 |
TN_US |
0.0008299 |
| 2020-04-01 |
TB_US |
0.0147059 |
| 2020-04-01 |
BOND_EMER |
-0.0124352 |
| 2020-04-01 |
GOLD |
-0.0032808 |
| 2020-04-02 |
EQ_US |
0.0230223 |
| 2020-04-02 |
EQ_NONUS_DEV |
0.0000000 |
| 2020-04-02 |
EQ_EMER |
0.0000000 |
| 2020-04-02 |
TN_US |
0.0008292 |
| 2020-04-02 |
TB_US |
0.0056711 |
| 2020-04-02 |
BOND_EMER |
0.0000000 |
| 2020-04-02 |
GOLD |
0.0291310 |
And you can see that we’ve recovered our original long form dataframe.
An example
One example where you’d be forced to pivot you long returns data frame to wide would be to calculate a correlation matrix:
dailyindex_df %>%
pivot_wider(names_from = ticker, values_from = returns) %>%
select(-date) %>%
cor(use = "pairwise.complete.obs", method='pearson') %>%
kable() %>%
kable_styling(position = 'center') %>%
scroll_box(width = '800px', height = '300px')
|
EQ_US |
EQ_NONUS_DEV |
EQ_EMER |
TN_US |
TB_US |
BOND_EMER |
GOLD |
| EQ_US |
1.0000000 |
0.1045511 |
0.1219745 |
-0.5935488 |
-0.4827843 |
0.1064579 |
0.2741258 |
| EQ_NONUS_DEV |
0.1045511 |
1.0000000 |
0.1216288 |
-0.2460011 |
-0.2961201 |
0.1418452 |
-0.4301298 |
| EQ_EMER |
0.1219745 |
0.1216288 |
1.0000000 |
-0.0362846 |
-0.2751978 |
0.1345682 |
0.1158572 |
| TN_US |
-0.5935488 |
-0.2460011 |
-0.0362846 |
1.0000000 |
0.9324163 |
0.3326693 |
0.1643955 |
| TB_US |
-0.4827843 |
-0.2961201 |
-0.2751978 |
0.9324163 |
1.0000000 |
0.3107047 |
0.2451740 |
| BOND_EMER |
0.1064579 |
0.1418452 |
0.1345682 |
0.3326693 |
0.3107047 |
1.0000000 |
0.3305851 |
| GOLD |
0.2741258 |
-0.4301298 |
0.1158572 |
0.1643955 |
0.2451740 |
0.3305851 |
1.0000000 |
You can see that we’ve also used the
select function from
dplyr to drop the date column before passing the wide data frame of returns to the
cor function for calculating the correlation matrix.
Plotting long format data
When you want to plot more than one variable on a single chart, long data is most definitely your friend:
dailyindex_df %>%
ggplot(aes(x = date, y = returns, colour = ticker)) +
geom_line()

Plotting each returns series in a grid is equally simple:
dailyindex_df %>%
ggplot(aes(x = date, y = returns)) +
geom_line() +
facet_wrap(~ticker)
Using wide-format data to make a similar plot would require repeated calls to
geom_line for each variable, which is quite painstaking and brittle.
For example, if something changes upstream, such as the addition of a new ticker to the data set, your code will also need to change in order to plot it. That’s not the case if we use long data with a column holding the ticker variable.
If you liked this you’ll probably like these too…
Financial Data Manipulation in dplyr for Quant Traders
How to Calculate Rolling Pairwise Correlations in the Tidyverse
How to Fill Gaps in Large Stock Data Universes Using tidyr and dplyr
 Plotting each returns series in a grid is equally simple:
Plotting each returns series in a grid is equally simple:
 Using wide-format data to make a similar plot would require repeated calls to
Using wide-format data to make a similar plot would require repeated calls to