
rsims is a new package for fast, realistic (quasi event-driven) backtesting of trading strategies in R.
Really?? Does the world really need another backtesting platform…??
It’s hard to argue with that sentiment. Zipline, QuantConnect, Quantstrat, Backtrader, Zorro… there are certainly plenty of good options out there. But allow me to offer a justification for why we felt the need to build our own tool.
It boiled down to a combination of:
- Wanting control and ownership over the internal workings of the simulator
- A need for speed
- A preference for simplicity
- A desire to focus less on indicators and signals and more on the problem of trading an existing set of positions into a target set of positions in the face of costs, risk, and other constraints.
rsims is a good choice if:
- Your research happens upstream of backtesting as opposed to consisting of backtesting (and this should nearly always be the case).
- Backtest speed is of interest to you, for example you have a large universe, higher resolution data, or some combination of the two. This makes it a good choice for classic quant equity style strategies.
It was originally developed to simulate a quant equity style strategy on cryptocurrencies.
While rsims is fast (it simulates trading on a set of weights and prices for a universe of 2,000 assets over 3,650 time steps in a shade over three seconds on my laptop), its speed does come with some trade-offs:
- Work is required by the user to ensure data inputs meet the backtesting engine’s requirements. For example, data alignment is critical, as there’s no indexing by human-readable timestamp.
- Related, there is danger if you get these input data wrong. For example, the simulation engine only performs cursory checks on the “correctness” of your inputs and will run to completion if these cursory checks pass, even if there are other issues with your data.
To help alleviate these issues, rsims includes a vignette on preparing input data. We also have some tools for checking and verifying input data in the works.
Let’s explore rsims.
Install and load
The easiest way to install and load rsims is using pacman::p_load_current_gh which wraps devtools::install_github and require:
pacman::p_load_current_gh("Robot-Wealth/rsims", dependencies = TRUE)
Usage
The key function is cash_backtest, an optimised, quasi event-driven backtesting function.
cash_backtest simulates trading into a set of weights (calculated upstream) subject to transaction cost and other constraints. It expects matrixes for the prices and theo_weights arguments, both with a timestamp as the first column and being of the same dimensions. Further details can be found in the function documentation. (?rsims::cash_backtest)
Approach to calculating position deltas
Currently, there is one module implemented for calculating optimal position deltas in the face of costs: the “no-trade region” approach. Here’s a good derivation of this approach from @macrocephalopod on Twitter.
This leads to a simple heuristic trading rule, which is theoretically optimal if your costs are linear and you don’t mind holding exposures within a certain range. Here’s how it works:
Given a trade_buffer parameter value of x:
- if the current weight for an asset,
w0is greater than the target weightwplusx, sell down the asset tow + x - if
w0is less thanw - x, buy the asset tow - x - if
w0is betweenw - xandw + x, do nothing
Linear costs is a reasonable assumption for certain cryptocurrency strategies since most crypto exchanges charge a fixed percentage commission fee. It’s not a good approach when your trading costs aren’t approximately linear, for example, small trading with a fixed minimum commission per trade.
This heuristic rule for trading position deltas is implemented as a C++ function: positionsFromNoTradeBuffer. We wrote it in C++ because it was relatively easy to do so thanks to the Rcpp package, and since it gets used in proportion to the number of timestamps multiplied by the number of assets, it can potentially be a bottleneck.
The intent is to implement other approaches in the future, such as numerical optimisation of the return-risk-cost problem, subject to constraints.
Cost model
Currently rsims implements a simplified “fixed percent of traded value” cost model. For some applications, market impact, spread, and commission might be reasonably represented by such a model. No attempt is made (yet) to explicitly account for these costs separately. Borrow, margin, and funding costs are not yet implemented.
Example
rsims was built with speed in mind, which required trading off certain conveniences such as holding weights and prices in long-format data frames indexed by a human-readable timestamp. Instead, it requires the user to ensure their input data meets some fairly strict requirements.
This example demonstrates how to wrangle price and target weight data into formats rsims can work with, and then how to simulate an example “quant equity” style strategy on cryptocurrencies.
Price and weight matrixes
cash_backtest requires two matrixes of identical dimensions. Both matrix’s first column needs to be a timestamp or date in Unix format.
The first input matrix contains prices, one column for each asset or product in the strategy’s universe.
The second matrix contains theoretical or ideal weights, again, one column for each asset in the strategy’s universe.
The timestamp should be aligned with the weights and prices such that on a single row, the price is the price at which you assume you can trade into the weight. This may require lagging of signals or weights upstream of the simulation and is up to the user.
Columns must map between the two matrixes:
- Column 1 is always the date or timestamp column
- Column 2 contains the prices and weights for the first asset
- Column 3 contains the prices and weights for the second asset
- etc
Let’s run through an example of how you might wrangle such input data using tools from the tidyverse.
If you load rsims, you’ll get in your global environment an example long-format data frame containing prices and target weights for a small universe of cryptocurrencies:
library(rsims) library(tidyverse) head(backtest_df_long) #> # A tibble: 6 x 4 #> # Groups: date [1] #> ticker date price_usd theo_weight #> <chr> <date> <dbl> <dbl> #> 1 BTC 2015-04-22 234. 0.1 #> 2 DASH 2015-04-22 3.24 -0.1 #> 3 DGB 2015-04-22 0.000110 -0.06 #> 4 DOGE 2015-04-22 0.000109 -0.02 #> 5 LTC 2015-04-22 1.44 0.02 #> 6 MAID 2015-04-22 0.0233 0.18
How you arrived at the weights for each product for each day is up to you – it will typically drop out of your upstream research process. But for the sake of our example, backtest_df_long contains weights for a simple cross-sectional momentum strategy on an evolving universe of cryptocurrencies.
Recall that we need to end up with two wide matrixes (date and prices, and date and weights), and that the matrixes must map column-wise.
One easy way to do that is to use tidyr::pivot_wider, which will guarantee that prices and weights will be mapped correctly, filling any missing price or weight with NA:
backtest_df <- backtest_df_long %>% pivot_wider(names_from = ticker, values_from = c(price_usd, theo_weight)) head(backtest_df) #> # A tibble: 6 x 37 #> # Groups: date [6] #> date price_usd_BTC price_usd_DASH price_usd_DGB price_usd_DOGE price_usd_LTC price_usd_MAID price_usd_VTC #> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 2015-04-22 234. 3.24 0.000110 0.000109 1.44 0.0233 0.00875 #> 2 2015-04-23 236. 3.67 0.000119 0.000111 1.45 0.0236 0.00890 #> 3 2015-04-24 231. 3.20 0.000133 0.000105 1.43 0.0224 0.00879 #> 4 2015-04-25 226. 3.09 0.000122 0.0000997 1.41 0.0225 0.00829 #> 5 2015-04-26 221. 3.05 0.000123 0.0000976 1.34 0.0207 0.00736 #> 6 2015-04-27 227. 2.98 0.000120 0.000105 1.38 0.0216 0.00714 #> # ... with 29 more variables: price_usd_XEM <dbl>, price_usd_XMR <dbl>, price_usd_XRP <dbl>, price_usd_ETH <dbl>, #> # price_usd_XLM <dbl>, price_usd_DCR <dbl>, price_usd_LSK <dbl>, price_usd_ETC <dbl>, price_usd_REP <dbl>, #> # price_usd_ZEC <dbl>, price_usd_WAVES <dbl>, theo_weight_BTC <dbl>, theo_weight_DASH <dbl>, theo_weight_DGB <dbl>, #> # theo_weight_DOGE <dbl>, theo_weight_LTC <dbl>, theo_weight_MAID <dbl>, theo_weight_VTC <dbl>, theo_weight_XEM <dbl>, #> # theo_weight_XMR <dbl>, theo_weight_XRP <dbl>, theo_weight_ETH <dbl>, theo_weight_XLM <dbl>, theo_weight_DCR <dbl>, #> # theo_weight_LSK <dbl>, theo_weight_ETC <dbl>, theo_weight_REP <dbl>, theo_weight_ZEC <dbl>, theo_weight_WAVES <dbl>
From this point, we can split our single wide matrix into two matrixes. Note that since matrixes must hold a common data type, our date column will be converted to a Unix-style timestamp. R takes care of that for us automatically.
First, the weights matrix, which will have some NA values where we didn’t have a weight for an asset on a particular day in our long data frame. It makes sense to replace these with zero:
# get weights as a wide matrix
# note that date column will get converted to unix timestamp
backtest_theo_weights <- backtest_df %>%
select(date, starts_with("theo_weight_")) %>%
data.matrix()
# NA weights should be zero
backtest_theo_weights[is.na(backtest_theo_weights)] <- 0
head(backtest_theo_weights, c(5, 5))
#> date theo_weight_BTC theo_weight_DASH theo_weight_DGB theo_weight_DOGE
#> [1,] 16547 0.10 -0.10 -0.06 -0.02
#> [2,] 16548 0.14 -0.06 -0.10 0.06
#> [3,] 16549 0.14 -0.10 0.10 -0.06
#> [4,] 16550 0.10 -0.10 0.06 -0.06
#> [5,] 16551 0.06 -0.06 0.14 -0.02
We do the same thing for our prices, but this time where an asset didn’t have a price (for example because it wasn’t in existence on a particular day), we leave the existing NA:
# get prices as a wide matrix
# note that date column will get converted to unix timestamp
backtest_prices <- backtest_df %>%
select(date, starts_with("price_")) %>%
rename_with(.cols = -date, .fn = ~ stringr::str_remove(.x, "price_usd_")) %>%
data.matrix()
head(backtest_prices, c(5, 5))
#> date BTC DASH DGB DOGE
#> [1,] 16547 233.8224 3.241223 0.0001098965 1.091501e-04
#> [2,] 16548 235.9333 3.667605 0.0001194309 1.113668e-04
#> [3,] 16549 231.4586 3.203421 0.0001334753 1.046427e-04
#> [4,] 16550 226.4460 3.093542 0.0001222808 9.972296e-05
#> [5,] 16551 220.5034 3.054431 0.0001227349 9.762035e-05
That’s all there is to it. At this point, we are ready to simulate trading according to our weights. cash_backtest returns a nicely formatted data frame of all the trades, commissions, and other accounting details for each asset for each day:
# simulation parameters initial_cash <- 10000 capitalise_profits <- FALSE # remain fully invested? trade_buffer <- 0. commission_pct <- 0. # simulation results_df <- cash_backtest( backtest_prices, backtest_theo_weights, trade_buffer, initial_cash, commission_pct, capitalise_profits ) head(results_df) #> # A tibble: 6 x 8 #> ticker Date Close Position Value Trades TradeValue Commission #> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Cash 2015-04-22 1 10000 10000 NA NA 0 #> 2 BTC 2015-04-22 234. 4.28 1000 4.28 1000 0 #> 3 DASH 2015-04-22 3.24 -309. -1000 -309. -1000 0 #> 4 DGB 2015-04-22 0.000110 -5459681. -600 -5459681. -600 0 #> 5 DOGE 2015-04-22 0.000109 -1832339. -200 -1832339. -200 0 #> 6 LTC 2015-04-22 1.44 139. 200 139. 200 0
From there, we can calculate performance statistics and plot a chart of portfolio NAV using convenient tidyverse tools. Here’s a helper function:
library(glue)
# plot equity curve from output of simulation
plot_results <- function(backtest_results, title = "Backtest results", trade_on = "close") {
equity_curve <- backtest_results %>%
group_by(Date) %>%
summarise(Equity = sum(Value, na.rm = TRUE))
fin_eq <- equity_curve %>%
tail(1) %>%
pull(Equity)
init_eq <- equity_curve %>%
head(1) %>%
pull(Equity)
total_return <- (fin_eq/init_eq - 1) * 100
days <- nrow(equity_curve)
ann_return <- total_return * 365/days
sharpe <- equity_curve %>%
mutate(returns = Equity/lag(Equity)- 1) %>%
na.omit() %>%
summarise(sharpe = sqrt(355)*mean(returns)/sd(returns)) %>%
pull()
equity_curve %>%
ggplot(aes(x = Date, y = Equity)) +
geom_line() +
labs(
title = title,
subtitle = glue(
"Costs {commission_pct*100}% trade value, trade buffer = {trade_buffer}, trade on {trade_on}
{round(total_return, 1)}% total return, {round(ann_return, 1)}% annualised, Sharpe {round(sharpe, 2)}"
)
) +
theme_bw()
}
plot_results(results_df)

Simulating costs
A reasonable estimate of trading costs for a crypto strategy is around 0.15% of traded volume. Here’s how we’d simulate that:
commission_pct <- 0.0015 cash_backtest( backtest_prices, backtest_theo_weights, trade_buffer, initial_cash, commission_pct = commission_pct, capitalise_profits ) %>% plot_results()

Finding an optimal trade buffer parameter
We can find a historically Sharpe-optimal value for our “no-trade region” parameter by iterating through reasonable values of the parameter and plotting the resulting backtested Sharpe ratio:
# calculate sharpe ratio from output of simulation
calc_sharpe <- function(backtest_results) {
backtest_results %>%
group_by(Date) %>%
summarise(Equity = sum(Value, na.rm = TRUE)) %>%
mutate(returns = Equity/lag(Equity)- 1) %>%
na.omit() %>%
summarise(sharpe = sqrt(355)*mean(returns)/sd(returns)) %>%
pull()
}
sharpes <- list()
trade_buffers <- seq(0, 0.15, by = 0.01)
for(trade_buffer in trade_buffers) {
sharpes <- c(
sharpes,
cash_backtest(
backtest_prices,
backtest_theo_weights,
trade_buffer,
initial_cash,
commission_pct,
capitalise_profits
) %>%
calc_sharpe()
)
}
sharpes <- unlist(sharpes)
data.frame(
trade_buffer = trade_buffers,
sharpe = sharpes
) %>%
ggplot(aes(x = trade_buffer, y = sharpe)) +
geom_line() +
geom_point(colour = "blue") +
geom_vline(xintercept = trade_buffers[which.max(sharpes)], linetype = "dashed") +
labs(
x = "Trade Buffer Parameter",
y = "Backtested Sharpe Ratio",
title = glue("Trade Buffer Parameter vs Backtested Sharpe, costs {commission_pct*100}% trade value"),
subtitle = glue("Max Sharpe {round(max(sharpes), 2)} at buffer param {trade_buffers[which.max(sharpes)]}")
) +
theme_bw()

Backtesting with this optimal value:
trade_buffer <- 0.06 results_df <- cash_backtest( backtest_prices, backtest_theo_weights, trade_buffer = trade_buffer, initial_cash, commission_pct, capitalise_profits ) plot_results(results_df)

It’s interesting to see how much the portfolio turned over with this approach. Here’s a plot of daily traded value by coin for a subset of our universe and for a random month:
results_df %>%
filter(
ticker %in% c("BTC", "LTC", "XEM", "DOGE"),
Date >= "2016-01-01",
Date < "2016-02-01"
) %>%
ggplot(aes(x = Date, y = TradeValue)) +
geom_bar(stat = "identity") +
facet_wrap(~ticker, ncol = 2) +
theme_bw()

Compared with a trade buffer parameter of zero (that is, always trading into the target weight):
results_df <- cash_backtest(
backtest_prices,
backtest_theo_weights,
trade_buffer = 0.0,
initial_cash,
commission_pct,
capitalise_profits
)
results_df %>%
filter(
ticker %in% c("BTC", "LTC", "XEM", "DOGE"),
Date >= "2016-01-01",
Date < "2016-02-01"
) %>%
ggplot(aes(x = Date, y = TradeValue)) +
geom_bar(stat = "identity") +
facet_wrap(~ticker, ncol = 2) +
theme_bw()

What’s next for rsims?
We’ll continue the development of rsims. In particular, we’re interested in implementing:
- Convenient performance reporting, possibly by integrating with existing tools such as
PerformanceAnalytics - Other trading mechanisms of interest, such as optimisation of the return-risk-cost problem subject to constraints
- Other cost models beyond the simple fixed percent of traded volume approach.
The focus will continue to be on speed and simplicity. If you’d like to contribute or explore the code, you can find rsims on Github here.

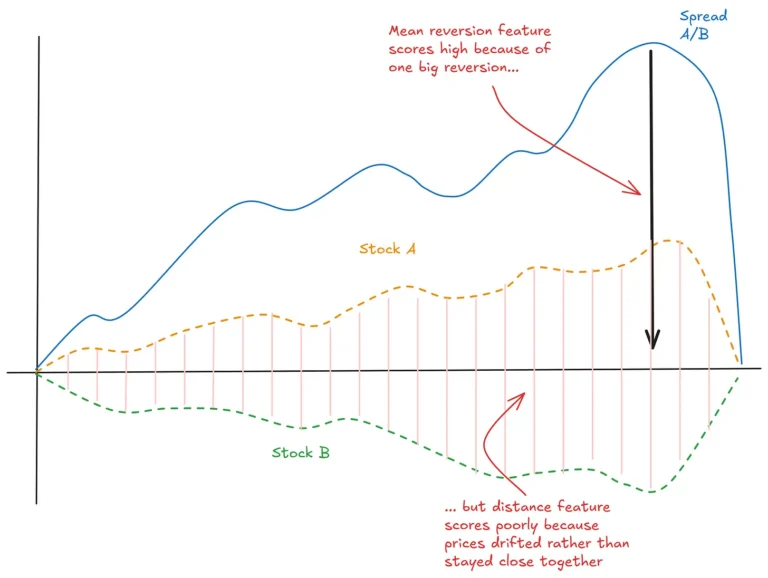
Great Post. One of the best I’ve read, thanks for that.
I have 2 questions:
1.- Can you teach us the C ++ code?
2.- I want to work with other and more updated assets, how do I do?
Thanks very much Elmer. Honestly, I’m not the best person to teach C++. To learn how to use C++ with R via Rcpp, I recommend going straight to the source and focusing on Dirk Eddelbuettel’s docs and Rcpp examples. You can browse the source for the Rcpp function we use in rsims here if that’s helpful.
rsimscan work with any price data and signals, so long as you provide them to thecash_accounting_backtestfunction in the correct format (wide matrixes with a date or timestamp column).