Quant trading
Evolving Thoughts on Data Mining
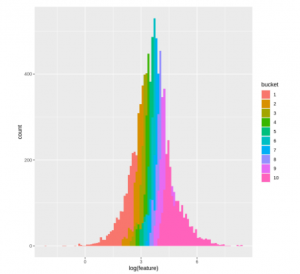
Several years ago, I wrote about some experimentation I’d done with data mining for predictive features from financial data. The
Several years ago, I wrote about some experimentation I’d done with data mining for predictive features from financial data. The
I have been sharing examples of simple real-time trading research on my Twitter account. I do this kind of thing a

I’m a big fan of Ernie Chan’s quant trading books: Quantitative Trading, Algorithmic Trading, and Machine Trading. There are some

The S&P index committee recently announced that Tesla, already one of the biggest stocks listed in the country, would be

Colaboratory, or Colab, is a hosted Jupyter notebook service requiring zero setup and providing free access to compute resources. It

You rarely meet a rich forex trader. I’ve met plenty of rich traders who trade quant factors or stat arb.

Here’s a chart of long-term asset performance…. The blue line shows returns from US stocks from 1900 to today.

I recently listened to a podcast about one of the earliest human civilizations – the ancient Sumerians. Apparently, our system

I was very sad to learn that Quantopian is shutting down its community services. Quantopian’s efforts to bring quant finance
You’ve probably noticed that there’s a US election on the horizon. This is an event of known uncertainty: a “known unknown”

This is a review of Positional Option Trading by Euan Sinclair. Trading books set a low bar for the reviewer.

This post presents an analysis of the SPY returns process using the QuantConnect research platform. QuantConnect is a strategy development